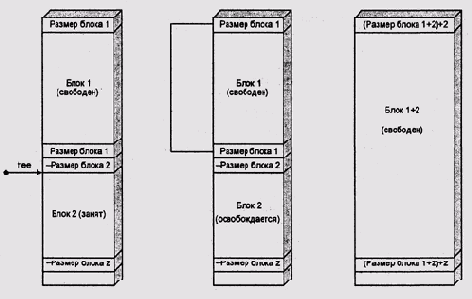
Объединение с использованием парных меток
Рисунок 4.8. Объединение с использованием парных меток
Примечание
Примечание
Это действительно большое преимущество, так как оно значительно облегчает выявление ошибок работы с указателями, о которых в руководстве по Zortech C/C++ сказано, что "опытные программисты, услышав это слово [ ошибка работы с указателями — прим. авт.], бледнеют и прячутся под стол" ([Zortech v3.xj).
Итак, наилучшим из известных универсальных алгоритмов динамического распределения памяти является алгоритм парных меток с объединением свободных блоков в двунаправленный кольцевой список и поиском по принципу first fit. Этот алгоритм обеспечивает приемлемую производительность почти для всех стратегий распределения памяти, используемых в прикладных программах.
Алгоритм парных меток был предложен Дональдом Кнутом в начале 60-х. В третьем издании классической книги [Кнут, 2000], этот алгоритм приводится под названием "освобождения с дескрипторами границ". В современных системах используются и более сложные структуры дескрипторов, но всегда ставится задача обеспечить поиск соседей блока по адресному про' странству за фиксированное время. В этом смысле, практически все современные подпрограммы динамического выделения памяти (в частности, реализации стандартной библиотеки языка С) используют аналоги алгоритма парных меток. Другие известные подходы либо просто хуже, чем этот, либо проявляют свои преимущества только в специальных случаях.
Реализация maiioc в библиотеке GNU LibC (реализация стандартной биб-иотеки языка С в рамках freeware проекта GNU Not Unix) (пример 4.3) использует смешанную стратегию: блоки размером более 4096 байт выделяются стратегией first fit из двусвязного кольцевого списка с использованием щклического просмотра, а освобождаются при помощи метода, который в мазанном ранее смысле похож на алгоритм парных меток. Все выделяемые образом блоки будут иметь размер, кратный 4096 байтам.
Блоки меньшего размера объединяются в очереди с размерами, пропорциональными степеням двойки, как в описанном далее алгоритме близнецов. Элементы этих очередей называются фрагментами (Рисунок 4.9). В отличие от алгоритма близнецов, мы не объединяем при освобождении парные фрагменты. Вместо этого, мы разбиваем 4-килобайтовый блок на фрагменты одинакового размера. Если, например, наша программа сделает запросы на 514 и 296 байт памяти, ей будут переданы фрагменты в 1024 и 512 байт соответственно. Под эти фрагменты будут выделены полные блоки в 4 килобайта, и внутри них будет выделено по одному фрагменту. При последующих запросах на фрагменты такого же размера будут использоваться свободные фрагменты этих блоков. Пока хотя бы один фрагмент блока занят, весь блок считается занятым. Когда же освобождается последний фрагмент, блок возвращается в пул.
Описатели блоков хранятся не вместе с самими блоками, а в отдельном динамическом массиве _heapihfo. Описатель заводится не на непрерывную последовательность свободных байтов, а на каждые 4096 байт памяти (в примере 4.3 именно это значение принимает константа BLOCKSIZE). Благодаря этому мы можем вычислить индекс описателя в _heapinfo, просто разделив на 4096 смещение освобождаемого блока от начала пула.
Для нефрагментированных блоков описатель хранит состояние (занят-свободен) и размер непрерывного участка, к которому принадлежит блок. Благодаря этому, как и в алгоритме парных меток, мы легко можем найти соседей освобождаемого участка памяти и объединить их в большой непрерывный участок.
Для фрагментированных блоков описатель хранит размер фрагмента, счетчик занятых фрагментов и список свободных. Кроме того, все свободные Фрагменты одного размера объединены в общий список — заголовки этих
списков собраны в массив _f raghead.
Используемая структура данных занимает больше места, чем применяемая в Классическом алгоритме парных меток, но сокращает объем списка свободных блоков и поэтому имеет более высокую производительность. Средний oбъем блока, выделяемого современными программами для ОС общего назначения, измеряется многими килобайтами, поэтому в большинстве случа-ев повышение накладных расходов памяти оказывается терпимо.
