Протоколы Internet
Статический алгоритм Хафмана
2.6.5 Статический алгоритм Хафмана
Семенов Ю.А. (ГНЦ ИТЭФ)
Статический алгоритм Хафмана можно считать классическим (см. также Р. Галлагер. Теория информации и надежная связь. “Советское радио”, Москва, 1974.) Определение статический в данном случае отностится к используемым словарям. Смотри также www.ics.ics.uci.edu/~dan/pubs/DataCompression.html (Debra A. Lelewer и Daniel S. Hirschberg).
Пусть сообщения m(1),…,m(n) имеют вероятности P(m(1)),… P(m(n)) и пусть для определенности они упорядочены так, что P(m(1)) і P(m(2)) і … і P(m(N)). Пусть x1,…, xn – совокупность двоичных кодов и пусть l1, l2,…, lN – длины этих кодов. Задачей алгоритма является установление соответствия между m(i) и xj. Можно показать, что для любого ансамбля сообщений с полным числом более 2 существует двоичный код, в котором два наименее вероятных кода xN и xN-1 имеют одну и ту же длину и отличаются лишь последним символом: xN имеет последний бит 1, а xN-1 – 0. Редуцированный ансамбль будет иметь свои два наименее вероятные сообщения сгруппированными вместе. После этого можно получить новый редуцированный ансамбль и так далее. Процедура может быть продолжена до тех пор, пока в очередном ансамбле не останется только два сообщения. Процедура реализации алгоритма сводится к следующему (см. рис. 2.6.5.1). Сначала группируются два наименее вероятные сообщения, предпоследнему сообщению ставится в соответствие код с младшим битом, равным нулю, а последнему – код с единичным младшим битом (на рисунке m(4) и m(5)). Вероятности этих двух сообщений складываются, после чего ищутся два наименее вероятные сообщения во вновь полученном ансамбле (m(3) и m`(4); p(m`(4)) = p(m(4)) + P(m(5))).
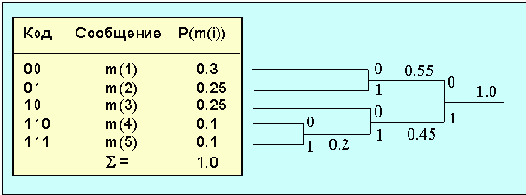
Рис. 2.6.5.1 Пример реализации алгоритма Хафмана
На следующем шаге наименее вероятными сообщениями окажутся m(1) и m(2). Кодовые слова на полученном дереве считываются справа налево. Алгоритм выдает оптимальный код (минимальная избыточность).
При использовании кодирования по схеме Хафмана надо вместе с закодированным текстом передать соответствующий алфавит. При передаче больших фрагментов избыточность, сопряженная с этим не может быть значительной.
Возможно применение стандартных алфавитов (кодовых таблиц) для пересылки английского, русского, французского и т.д. текстов, программных текстов на С++, Паскале и т.д. Кодирование при этом не будет оптимальным, но исключается статистическая обработка пересылаемых фрагментов и отпадает необходимость пересылки кодовых таблиц.
