Протоколы Internet
Коррекция ошибок
2.8 Коррекция ошибок
Семенов Ю.А. (ГНЦ ИТЭФ)

Исправлять ошибки труднее, чем их детектировать или предотвращать. Процедура коррекции ошибок предполагает два совмещенные процесса: обнаружение ошибки и определение места (идентификация сообщения и позиции в сообщении). После решения этих двух задач, исправление тривиально – надо инвертировать значение ошибочного бита. В наземных каналах связи, где вероятность ошибки невелика, обычно используется метод детектирования ошибок и повторной пересылки фрагмента, содержащего дефект. Для спутниковых каналов с типичными для них большими задержками системы коррекции ошибок становятся привлекательными. Здесь используют коды Хэмминга или коды свертки.
Код Хэмминга представляет собой блочный код, который позволяет выявить и исправить ошибочно переданный бит в пределах переданного блока. Обычно код Хэмминга характеризуется двумя целыми числами, например, (11,7) используемый при передаче 7-битных ASCII-кодов. Такая запись говорит, что при передаче 7-битного кода используется 4 контрольных бита (7+4=11). При этом предполагается, что имела место ошибка в одном бите и что ошибка в двух или более битах существенно менее вероятна. С учетом этого исправление ошибки осуществляется с определенной вероятностью. Например, пусть возможны следующие правильные коды (все они, кроме первого и последнего, отстоят друг от друга на расстояние 4):
00000000
11110000
00001111
11111111
При получении кода 00000111 не трудно предположить, что правильное значение полученного кода равно 00001111. Другие коды отстоят от полученного на большее расстояние Хэмминга.
Рассмотрим пример передачи кода буквы s = 0x073 = 1110011 с использованием кода Хэмминга (11,7).
Символами * помечены четыре позиции, где должны размещаться контрольные биты. Эти позиции определяются целой степенью 2 (1, 2, 4, 8 и т.д.). Контрольная сумма формируется путем выполнения операции XOR (исключающее ИЛИ) над кодами позиций ненулевых битов. В данном случае это 11, 10, 9, 5 и 3. Вычислим контрольную сумму:
| 11 = | 1011 | ||
| 10 = | 1010 | ||
| 09 = | 1001 | ||
| 05 = | 0101 | ||
| 03 = | 0011 | ||
| s = | 1110 |
/p> Таким образом, приемник получит код:
| Позиция бита: | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Значение бита: | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
| 11 = | 1011 |
| 10 = | 1010 |
| 09 = | 1001 |
| 08 = | 1000 |
| 05 = | 0101 |
| 04 = | 0100 |
| 03 = | 0011 |
| 02 = | 0010 |
| s = | 0000 |
| 11 = | 1011 |
| 10 = | 1010 |
| 09 = | 1001 |
| 08 = | 1000 |
| 07 = | 0111 |
| 05 = | 0101 |
| 04 = | 0100 |
| 03 = | 0011 |
| 02 = | 0010 |
| s = | 0111 |
В общем случае код имеет N=M+C бит и предполагается, что не более чем один бит в коде может иметь ошибку. Тогда возможно N+1 состояние кода (правильное состояние и n ошибочных). Пусть М=4, а N=7, тогда слово-сообщение будет иметь вид: M4, M3, M2, C3, M1, C2, C1. Теперь попытаемся вычислить значения С1, С2, С3. Для этого используются уравнения, где все операции представляют собой сложение по модулю 2:
С1 = М1 + М2 + М4
С2 = М1 + М3 + М4
С3 = М2 + М3 + М4
Для определения того, доставлено ли сообщение без ошибок, вычисляем следующие выражения (сложение по модулю 2):
С11 = С1 + М4 + М2 + М1
С12 = С2 + М4 + М3 + М1
С13 = С3 + М4 + М3 + М2
Результат вычисления интерпретируется следующим образом.
| С11 | С12 | С13 | Значение |
| 1 | 2 | 4 | Позиция бит |
| 0 | 0 | 0 | Ошибок нет | 0 | 0 | 1 | Бит С3 не верен |
| 0 | 1 | 0 | Бит С2 не верен |
| 0 | 1 | 1 | Бит М3 не верен> |
| 1 | 0 | 0 | Бит С1 не верен> |
| 1 | 0 | 1 | Бит М2 не верен |
| 1 | 1 | 0 | Бит М1 не верен |
| 1 | 1 | 1 | Бит М4 не верен |
/p> Описанная схема легко переносится на любое число n и М.
Число возможных кодовых комбинаций М помехоустойчивого кода делится на n классов, где N – число разрешенных кодов. Разделение на классы осуществляется так, чтобы в каждый класс вошел один разрешенный код и ближайшие к нему (по расстоянию Хэмминга) запрещенные коды. В процессе приема данных определяется, к какому классу принадлежит пришедший код. Если код принят с ошибкой, он заменяется ближайшим разрешенным кодом. При этом предполагается, что кратность ошибки не более qm.
Можно доказать, что для исправления ошибок с кратностью не более qmm (как правило, оно выбирается равным D = 2qm +1). В теории кодирования существуют следующие оценки максимального числа N n-разрядных кодов с расстоянием D.
| d=1 | n=2n |
| d=2 | n=2n-1 |
| d=3 |
n 2n /(1+n) |
| d=2q+1 |
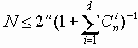 |
k= n – log(n+1),
откуда следует (логарифм по основанию 2), что k может принимать значения 0, 1, 4, 11, 26, 57 и т.д., это и определяет соответствующие коды Хэмминга (3,1); (7,4); (15,11); (31,26); (63,57) и т.д.
Циклические коды
Обобщением кодов Хэмминга являются циклические коды BCH (Bose-Chadhuri-Hocquenghem). Это коды с широким выбором длины и возможностей исправления ошибок. Циклические коды характеризуются полиномом g(x) степени n-k, g(x) = 1 + g1x + g2x2 + … + xn-k. g(x) называется порождающим многочленом циклического кода. Если многочлен g(x) n-k и является делителем многочлена xn + 1, то код C(g(x)) является линейным циклическим (n,k)-кодом. Число циклических n-разрядных кодов равно числу делителей многочлена xn + 1.
При кодировании слова все кодовые слова кратны g(x). g(x) определяется на основе сомножителей полинома xn +1 как:
xn +1 = g(x)h(x)
Например, если n=7 (x7+1), его сомножители (1 + x + x3)(1 + x + x2 + x4), а g(x) = 1+x + x3.
Чтобы представить сообщение h(x) в виде циклического кода, в котором можно указать постоянные места проверочных и информационных символов, нужно разделить многочлен xn-kh(x) на g(x) и прибавить остаток от деления к многочлену xn-kh(x). См. Л.Ф. Куликовский и В.В. Мотов, “Теоретические основы информационных процессов”. Москва “Высшая школа” 1987. Привлекательность циклических кодов заключается в простоте аппаратной реализации с использованием сдвиговых регистров.
Пусть общее число бит в блоке равно N, из них полезную информацию несут в себе K бит, тогда в случае ошибки, имеется возможность исправить m бит. Таблица 2.8.1 содержит зависимость m от N и K для кодов ВСН.
Таблица 2.8.1
| Общее число бит N | Число полезных бит М | Число исправляемых бит m |
| 31 | 26 | 1 |
| 21 | 2 | |
| 16 | 3 | |
| 63 | 57 | 1 |
| 51 | 2 | |
| 45 | 3 | |
| 127 | 120 | 1 |
| 113 | 2 | |
| 106 | 3 |
Таблица 2.8.2
| Число полезных бит М | Число избыточных бит (n-m) | ||
| 6 | 7 | 8 | |
| 32 | 48% | 74% | 89% |
| 40 | 36% | 68% | 84% |
| 48 | 23% | 62% | 81% |
Применение кодов свертки позволяют уменьшить вероятность ошибок при обмене, даже если число ошибок при передаче блока данных больше 1.
Линейные блочные коды
Блочный код определяется, как набор возможных кодов, который получается из последовательности бит, составляющих сообщение. Например, если мы имеем К бит, то имеется 2К возможных сообщений и такое же число кодов, которые могут быть получены из этих сообщений. Набор этих кодов представляет собой блочный код. Линейные коды получаются в результате перемножения сообщения М на порождающую матрицу G[IA]. Каждой порождающей матрице ставится в соответствие матрица проверки четности (n-k)*n. Эта матрица позволяет исправлять ошибки в полученных сообщениях путем вычисления синдрома. Матрица проверки четности находится из матрицы идентичности i и транспонированной матрицы А. G[IA] ==> H[ATI].
| I | A | AT [ZEBR_TAG_/table> Если 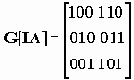 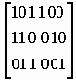 Синдром полученного сообщения равен S = [полученное сообщение]. [матрица проверки четности]. Если синдром содержит нули, ошибок нет, в противном случае сообщение доставлено с ошибкой. Если сообщение М соответствует М=2k, а k =3 высота матрицы, то можно записать восемь кодов: |
/p>
| Сообщения | Кодовые вектора | Вычисленные как |
| M1 = 000 | V1 = 000000 | M1.G |
| M2 = 001 | V2 = 001101 | M2.G |
| M3 = 010 | V3 = 010011 | M3. G |
| M4 = 100 | V4 = 100110 | M4. G |
| M5 = 011 | V5 = 011110 | M5.G |
| M6 = 101 | V6 = 101011 | M6 .G |
| M7 = 110 | V7 = 110101 | M7 .G |
| M8 = 111 | V8 = 111000 | M8 .G |
Таблица 2.8.3. Стандартный массив для кодов (6,3)
| 000000 | 001101 | 010011 | 100110 | 011110 | 101011 | 110101 | 111000 |
| 000001 | 001100 | 010010 | 100111 | 011111 | 101010 | 110100 | 111001 |
| 000010 | 001111 | 010001 | 100100 | 011100 | 101001 | 110111 | 111010 |
| 000100 | 001001 | 010111 | 100010 | 011010 | 101111 | 110001 | 111100 |
| 001000 | 000101 | 011011 | 101110 | 010110 | 100011 | 111101 | 110000 |
| 010000 | 011101 | 000011 | 110110 | 001110 | 111011 | 100101 | 101000 |
| 100000 | 101101 | 110011 | 000110 | 111110 | 001011 | 010101 | 011000 |
| 001001 | 000100 | 011010 | 101111 | 010111 | 100010 | 111100 | 011001 |
Синдром равен произведению левой колонки (CL "coset leader") стандартного массива на транспонированную матрицу контроля четности HT.
| Синдром = CL . HT | Левая колонка стандартного массива |
| 000 | 000000 |
| 001 | 000001 |
| 010 | 000010 |
| 100 | 000100 |
| 110 | 001000 |
| 101 | 010000 |
| 011 | 100000 |
| 111 | 001001 |
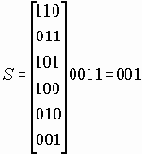
этот результат указывает на место ошибки, истинное значение кода получается в результате операции XOR:
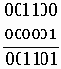
Смотри также
www.cs.ucl.ac.uk/staff/S.Bhatti/D51-notes/node33.html (Saleem Bhatti).
