в другую функцию, которая отображает
Обратите внимание, что -> имеет правую ассоциативность:
insert_element: int -> (int list -> int list)
Функция отображает целое число в другую функцию, которая отображает список целых в список целых. При помощи частичных вычислений мы можем создавать новые функции подобно следующей:
fun insert_4 = insert_element 4
которая вставляет 4 в список целых.
В отличие от процедурной программы для того же самого алгоритма здесь нет никаких индексов и никаких for-циклов. Кроме того, ее можно легко обобщить для сортировки объектов других типов, просто заменяя операцию «<» соответствующей булевой функцией для сравнения двух значений рассматриваемого типа. Чтобы создать список, явные указатели не нужны; они заданы неявно в представлении данных. Конечно, сортировка списков в любом языке не так эффективна, как сортировка массива «на своем месте», но для многих приложений, использующих списки, вполне практична.
Определение новых типов
Повсюду в этой книге мы видели, что определение новых типов весьма существенно, если язык программирования должен моделировать реальные объекты. Современные функциональные языки программирования также имеют эту возможность. Определим (рекурсивный) тип для деревьев, узлы которых помечены целыми числами:
datatype int tree =
Empty
| T of (int tree x int x int tree)
Это следует читать так:
int tree является новым типом данных, значения которого: 1) новое константное значение Empty (пусто) или 2) значение, которое сформировано конструктором Т, примененным к тройке, состоящей из дерева, целого числа и другого дерева.
Определив новый тип, мы можем написать функции, которые обрабатывают дерево.
Например:
fun sumtree Empty = О
| sumtree T(left, value, right) =
(sumtree left) + value + (sumtree right)
суммирует значения, помечающие узлы дерева, и:
вычисляет минимальное из всех значений,
fun mintree Empty = maxint
| mintree T(left, value, right) =
min left (min value (mintree right))
вычисляет минимальное из всех значений, помечающих узлы, возвращая наибольшее'целое число maxint для пустого дерева.
Все стандартные алгоритмы обработки деревьев можно написать аналогичным образом: определить новый тип данных, который соответствует древовидной структуре, а затем написать функции для этого типа. При этом никакие явные указатели или циклы не нужны, «работают» только рекурсия и сопоставление с образцом.
16.4. Функции более высокого порядка
В функциональном программировании функция является обычным объектом, имеющим тип, поэтому она может быть аргументом других функций. Например, мы можем создать обобщенную (родовую) форму для insert_element (вставить элемент), просто добавляя функцию compare как дополнительный аргумент:
fun general_insert_element compare x [ ] = [х]
| general_insert_element compare x head:: tail =
if compare x head
then x::head::tail
else head:: (general_insert_element compare x tail)
Если string_compare является функцией от string к boolean:
string_compare: (string x string)—> bool
применение general_insert_element к этому аргументу:
fun string_insert = general_insert_element string_compare
дает функцию следующего типа:
string -> string list -> string list
Обратите внимание, что, в отличие от процедурных языков, это обобщение достигается естественно, без какого-либо дополнительного синтаксиса или семантики, наподобие generic или template.
Но какой тип у general_insert_element? Первый аргумент должен иметь тип «функция от пары чего-либо к булеву значению», второй аргумент должен иметь тип этого самого «чего-либо», а третий параметр является списком этих «чего-либо». Типовые переменные (type variables) используются в качестве краткой записи для этого «чего-либо», и, таким образом, тип функции будет следующим:
в языке ML как идентификаторы
general_insert_element: (('t x 't) -> bool) -> 't -> 't list
где типовые переменные записаны в языке ML как идентификаторы с предшествующим
апострофом
Использование функций более высокого порядка, т. е. функций, аргументами которых являются функции, не ограничено такими статическими конструкциями, как обобщения. Чрезвычайно полезная функция — тар:
fun map f [] = [ ]
| mар f head :: tail = (f head):: (map f tail)
Эта функция применяет первый аргумент к списку значений, производя список результатов. Например:
map even [1, 3, 5, 2, 4, 6] = [false, false, false, true, true, true]
map min [(1,5), (4,2), (8,1)] = [1,2,1]
Этого фактически невозможно достичь в процедурных языках; самое большее, мы могли бы написать подпрограмму, которая получает указатель на функцию в качестве аргумента, но мы потребовали бы разных подпрограмм для каждой допустимой сигнатуры аргумента функции.
Обратите внимание, что эта конструкция надежная. Тип тар следующий:
mар: (t1 -> t2) -> 't1 list -> t2 list
Это означает, что элементы списка аргументов t1 list все должны быть совместимы с аргументом функции t1, а список результата t2 list будет состоять только из элементов, имеющих тип результата функции t2.
Функции более высокого порядка абстрагируются от большинства управляющих структур, которые необходимы в процедурных языках. В другом примере функция accumulate реализует «составное» применение функции, а не создает список результатов, подобно mар:
fun accumulate f initial [] = initial
| accumulate f initial head::tail - accumulate f (f initial head) tail
Функция accumulate может использоваться для создания ряда полезных функций. Функции
fun minlist = accumulate min maxint
fun sumlist = accumulate "+" 0
вычисляют минимальное значение целочисленного списка и сумму целочисленного списка соответственно.
Функции более высокого порядка не
Например:
minlist [3, 1,2] =
accumulate min maxint [3, 1,2] =
accumulate min (min maxint 3) [1,2] =
accumulate min 3 [1, 2] =
accumulate min (min 3 1) [2] =
accumulate min 1 [2] =
accumulate min (min 1 2) [] =
accumulate min 1 [] =
1
Функции более высокого порядка не ограничиваются списками; можно написать функции, которые обходят деревья и применяют функцию в каждом узле. Кроме того, функции могут быть определены на типовых переменных так, чтобы их можно было использовать без изменений при определении новых типов данных.
16.5. Ленивые и жадные вычисления
В процедурных языках мы всегда предполагаем, что фактические параметры вычисляются до вызова функции:
|
C |
Для обозначения такой методики используется термин — жадные вычисления. Однако жадные вычисления имеют свои собственные проблемы, с которыми мы столкнулись в if-операторах (см. раздел 6.2), когда пришлось определить специальную конструкцию для укороченного вычисления:
|
Ada |
Как должно быть определено условное выражение
if с then e1 else e2
в функциональном языке программирования? При жадном вычислении мы вычислили бы с, е1 и е2 и только затем выполнили условную операцию. Конечно, это неприемлемо: следующее выражение нельзя успешно выполнить, если используются жадные вычисления, так как невозможно взять первый элемент пустого списка:
if list = [] then [] else hd list
Чтобы решить эту проблему, в язык ML введено специальное правило для вычисления if-функции: сначала вычисляется условие с, и только после этого вычисляется один из двух вариантов.
Ситуация была бы намного проще, если бы использовались ленивые вычисления, где аргумент вычисляется только, когда он необходим, и только в нужном объеме.
Например, мы могли бы определить if как обычную функцию:
Когда применяется if, функция просто
fun if true х у = х
| if false х у = у
Когда применяется if, функция просто применяется к первому аргументу, производя следующее:
(if list = [] [] hd list) [] =
if [] = [] [] hd [] =
if true [] hd [] =
[]
и мы не пытаемся вычислить hd [].
Ленивое вычисление аналогично механизму вызова параметра по имени (call-by-name) в процедурных языках, где фактический параметр вычисляется каждый раз заново, когда используется формальный параметр. Этот механизм в процедурных языках сомнителен из-за возможности побочных эффектов, которые не позволяют сделать оптимизацию путем вычисления и сохранения результата для многократного использования. В функциональном программировании, свободном от побочных эффектов, такой проблемы нет, и языки, использующие ленивые вычисления (например, Miranda), были реализованы. Ленивые вычисления могут быть менее эффективными, чем жадные, но у них есть значительные преимущества.
В ленивых вычислениях больше всего привлекает то, что можно делать пошаговые вычисления и использовать их, чтобы запрограммировать эффективные алгоритмы. Например, рассмотрим дерево целочисленных значений, чей тип мы определили выше. Вы можете запрограммировать алгоритм, который сравнивает два дерева, чтобы выяснить, имеют ли они одинаковый набор значений при некотором упорядочении узлов. Это можно записать следующим образом:
fun equal_nodes t1 t2 = compare_lists (tree_to_list t1) (tree_to_list t2)
Функция tree_to_list обходит дерево и создает список значений в узлах; соm-pare_lists проверяет, равны ли два списка. При жадных вычислениях оба дерева полностью преобразуются в списки до того, как будет выполнено сравнение, даже если при обходе выяснится, что первые узлы не равны! При ленивых вычислениях функции нужно вычислять только в том объеме, который необходим для ответа на поставленный вопрос.
Функции compare_lists и tree_to_list определены следующим образом:
Ленивые вычисления, например, могли бы
fun compare_lists [] [] = true
| compare_lists head::tail1 head::tail2 = compare_lists tail1 tail2
| compare_lists list1 Iist2 = false
fun tree_to_list Empty = []
| tree_to_listT(left, value, right) =
value :: append (tree_to_list left) (tree_to_list right)
Ленивые вычисления, например, могли бы происходить следующим образом (мы использовали сокращенные имена функций сmp и ttl, а многоточием обозначили очень большое поддерево):
cmp ttl T(T(Empty,4,Empty), 5, . . .)
ttl T(T(Empty,6,Empty), 5,...) =
cmp 5:: append (ttl T(Empty,4,Empty)) (ttl.. .)
5:: append (ttl T(Empty,6,Empty)) (ttl.. .) =
cmp append (ttl T(Empty,4,Empty)) (ttl.. .)
append (ttl T(Empty,6,Empty)) (ttl. ..) =
…
cmp 4:: append [] (ttl. . .)
6:: append [] (ttl. ..) =
false
Вычисления, выполняемые только по мере необходимости, позволили полностью избежать ненужного обхода правого поддерева. Чтобы достичь того же самого эффекта в языке, подобном ML, который использует жадные вычисления, придется применять специальные приемы.
Дополнительное преимущество ленивых вычислений состоит в том, что они подходят для интерактивного и системного программирования. Ввод, скажем, с терминала рассматривается просто как потенциально бесконечный список значений. При ленивых вычислениях, конечно, никогда не рассматривается весь список: вместо этого всякий раз, когда пользователь вводит значение, забирается первый элемент списка.
16.6. Исключения
Вычисление выражения в языке ML может привести к исключению. Существуют стандартные исключения, которые в основном возникают при вычислениях со встроенными типами, например при делении на ноль или попытке взять первый элемент пустого списка. Программист также может объявлять исключения, у которых могут быть необязательные параметры:
После этого может возникнуть исключение,
exception BadParameter of int;
После этого может возникнуть исключение, которое можно обработать:
fun only_positive n =
if n <= 0 then raise BadParameter n
else...
val i = ...;
val j = only_positive i
handle
BadParameter 0 => 1;
BadParameter n => abs n;
Функция only_positive возбудит исключение BadParameter, если параметр не положителен. При вызове функции обработчик исключения присоединяется к вызывающему выражению, определяя значение, которое будет возвращено, если исключение наступит. Это значение можно использовать для дальнейших вычислений в точке, где произошло исключение; в этом случае оно используется только как значение, возвращаемое функцией.
16.7. Среда
Помимо определений функций и вычисления выражений программа на языке ML может содержать объявления:
val i = 20
val'S = "Hello world"
Таким образом, в языке ML есть память, но, в отличие от процедурных языков, эта память необновляемая; в данном примере нельзя «присвоить» другое значение i или s. Если мы теперь выполним:
val i = 35
будет создано новое именованное значение, скрывающее старое значение, но не заменяющее содержимое i новым значением. Объявления в языке ML аналогичны объявлениям const в языке С в том смысле, что создается объект, который нельзя изменить; однако повторное определение в языке ML скрывает предыдущее, в то время как в языке С запрещено повторно объявлять объект в той же самой области действия.
Блочное структурирование можно делать, объявляя определения или выражения как локальные. Синтаксис для локализации внутри выражения показан в следующем примере, который вычисляет корни квадратного уравнения, используя локальное объявление для дискриминанта:
val а = 1.0 and b = 2.0 and с = 1.0
let
D = b*b-4.0*a*c
in
((- b + D)/2.0*a, (- b - D)/2.0*a )
с именем. Набор всех таких
end
Каждое объявление связывает (binds) значение с именем. Набор всех таких связей, действующих в какой-либо момент времени, называется средой (environment), и мы говорим, что выражение вычислено в контексте среды. Мы фактически обсуждали среды детально в контексте областей действия и видимости в процедурных языках; различие состоит в том, что связывания не могут изменяться в среде функционального программирования.
Очень просто выглядит расширение, позволяющее включать в среду абстрактные типы данных. Это делается присоединением набора функций к объявлению типа:
abstype int tree =
Empty
| Т of (int tree x int x int tree)
with
fun sumtree t = . . .
fun equal_nodes t1 t2 = .. .
end
Смысл этого объявления состоит в том, что только перечисленные функции имеют доступ к конструкторам абстрактного типа аналогично приватному типу в языке Ada или классу в языке C++ с приватными (private) компонентами. Более того, абстрактный тип может быть параметризован типовой переменной:
abstype 't tree = . . .
что аналогично созданию родовых абстрактных типов данных в языке Ada.
Язык ML включает очень гибкую систему для определения и управления модулями. Основное понятие — это структура (structure), которая инкапсулирует среду, состоящую из объявлений (типов и функций), аналогично классу в языке C++ или пакету в языке Ada, определяющему абстрактный тип данных. Однако в языке ML структура сама является объектом, который имеет тип, названный сигнатурой (signature). Структурами можно управлять, используя функторы (functors), которые являются функциями, отображающими одну структуру в другую. Это — обобщение родового понятия, которое отображает пакет или шаблоны класса в конкретные типы. Функторы можно использовать, чтобы скрыть или совместно использовать информацию в структурах. Детали этих понятий выходят за рамки данной книги, и заинтересованного читателя мы отсылаем к руководствам по языку ML.
Функциональные языки программирования можно использовать
Функциональные языки программирования можно использовать для написания кратких, надежных программ для приложений, имеющих дело со сложными структурами данных и сложными алгоритмами. Даже если эффективность функциональной программы неприемлема, ее все же можно использовать как прототип или рабочую спецификацию для создаваемой программы.
16.8. Упражнения
1. Какой тип у карризованной функции min_c?
fun min_c х у = if x < у then x else у
2. Выведите типы sumtree и mintree.
3. Опишите словами определение general_insert_element.
4. Напишите функцию для конкатенации списков, а затем покажите, как ту же самую функцию можно определить с помощью accumulate.
5. Напишите функцию, которая берет список деревьев и возвращает список минимальных значений в каждом дереве.
6. Выведите типы compare_lists и tree_to_list.
7. Что делает следующая программа? Какой тип у функции?
fun filter f[] = []
| filter f h ::t = h:: (filter f t), if f h = true
| filter f h :: t = filter f t, otherwise
8. Стандартное отклонение последовательности чисел (х\, . .. , х„) определяется как квадратный корень из среднего значения квадратов чисел минус квадрат среднего значения. Напишите программу на языке ML, которая вычисляет стандартное отклонение списка чисел. Подсказка: используйте тар и accumulate.
9. Напишите программу на языке ML для поиска совершенных чисел; п > 2 — совершенное число, если множители я (не включая п) в сумме дают п. Например, 1 +2 + 4 + 7+ 14 = 28.В общих чертах программа будет выглядеть как:
fun isperfect n =
let fun addfactors...
in addfactors(n div 2) = n end;
10. Сравните исключения в языке ML с исключениями в языках Ada, C++ и Eiffel.
Глава 17
Логическое программирование основано на том
Логическое программирование
Логическое программирование основано на том наблюдении, что формулы математической логики можно интерпретировать как спецификацию вычисления. Стиль программирования при этом становится скорее декларативным, чем процедурным. Мы не выдаем команды, сообщающие компьютеру, что делать; вместо этого мы описываем связь между входными и выходными данными и предоставляем компьютеру «догадаться», как получить из входа выход. В пределах, в которых этого удается достичь, логическое программирование обеспечивает значительно более высокий уровень абстракции с соответствующим преимуществом чрезвычайной краткости программ.
Есть две основные абстракции, которые характеризуют логическое программирование. Суть первой состоит в том, что от таких управляющих операторов, как хорошо известные for и if, мы отказываемся полностью. Вместо них «компилятор» предоставляет чрезвычайно мощный механизм управления, который единообразно применяется ко всей программе. Механизм основан на понятии доказательства в математической логике: программа рассматривается не как пошаговый алгоритм, а как набор логических формул, которые предполагаются истинными (аксиомы), а вычисление — как попытка доказать формулу на основе аксиом программы.
Суть второй абстракции в том, что больше не используются операторы присваивания и явные указатели; вместо этого для создания и декомпозиции структур данных используется обобщенный механизм сопоставления с образцом, названный унификацией. При унификации создаются неявные указатели на компоненты структур данных, но программист видит только абстрактные структуры данных, такие как списки, записи и деревья.
После того как мы обсудим «чистое» логическое программирование, мы опишем компромиссы, введенные в языке Prolog, первом и все еще очень популярном языке логического программирования, используемом на практике.
В то время как проделать вручную вышеупомянутое вычисление довольно утомительно, для компьютера это всего лишь случай без конца повторяющейся задачи, с которой он превосходно справляется.
Для выполнения логической программы набор
Для выполнения логической программы набор логических формул (программа) и формула-цель, например:
"wor" =>"Hello world"?
предлагаются программной системе, которая названа машиной вывода, потому что она из одних формул выводит другие, являющиеся их следствием, пока проблема не будет решена. Метод логического вывода проверяет, можно ли доказать целевую формулу, исходя из аксиом, т.е. формул программы, которые приняты за истинные. Ответом может быть и «да», и «нет», что в логическом программировании называется «успехом» или «неуспехом». «Неуспех» мог быть получен из-за того, что цель не следует из программы, например, "wro" не является подстрокой "Hello world", или из-за неправильности программы, например, если мы пропустили одну из формул программы. Возможен и третий вариант, когда поиск машины вывода будет продолжаться без выбора того или иного ответа, и, так же как это может случиться с while-циклом в языке С, никогда не завершится.
Основные понятия логического программирования:
• Программа является декларативной и состоит исключительно из формул математической логики.
• Каждый набор формул для того же самого предиката (такого как «с») интерпретируется как процедура (возможно, рекурсивная).
• Конкретное вычисление определяется предложенной целью, т.е. формулой, о которой нужно выяснить, является ли она следствием программы.
• Компилятор является машиной вывода, которая по мере возможности ищет доказательство цели из программы.
Таким образом, каждую логическую программу можно прочитать двояко: как набор формул и как спецификацию вычисления. В некотором смысле, логическая программа — это минимальная программа. В разработке программного обеспечения вас обучают точно определять смысл программы перед попыткой ее реализовать, и для точной спецификации используется формальная нотация, обычно некоторая форма математической логики.
фикация является программой, то делать
Если специ фикация является программой, то делать больше нечего, и тысячи программистов можно заменить горсткой логиков. Причина того, что логическое программирование нетривиально, состоит в том, что чистая логика недостаточно эффективна для практического программирования, и поэтому есть этап, который должен быть пройден от научной теоретической логики до ее инженерных приложений в программировании.
В логическом программировании нет никаких «операторов присваивания», потому что управляющая структура единообразна для всех программ и состоит из поиска доказательства формулы. Поиск решений проблемы, конечно, не нов; новым является предположение, что поиск решений вычислительных проблем возможен в рамках общей схемы логических доказательств. Логика стала логическим программированием, когда было обнаружено, что, ограничивая структуру формул и способы, которыми делается поиск доказательств, можно сохранить простоту логических утверждений и тем не менее искать решения проблем эффективным способом. Перед объяснением как это делается, мы должны обсудить, как обрабатываются данные в логическом программировании.
17.2. Унификация
Хорновский клоз (Нот clause) — это формула, в которой с помощью конъюнкции («и»)элементарных формул выводится одиночная элементарная формула:
(s=>t)<=(t = tl||t2)^(S=>tl)
Логическое программирование основано на том наблюдении, что, ограничивая формулы хорновскими клозами, мы получаем правильное соотношение между выразительностью и эффективностью вывода. Такие факты, как t => t, являются выводами, которые ниоткуда не следуют, т. е. они всегда истинны. Вывод также называется головой формулы, потому при записи в инверсной форме оно появляется в формуле первым.
Чтобы инициализировать вычисление логической программы, задается цель:
"wof" => "Hello world"?
Машина вывода пытается сопоставить цель и вывод формулы.
чае соответствие устанавливается сразу же:
В данном слу чае соответствие устанавливается сразу же: "wor" соответствует переменной s, a "Hello world" — переменной t. Это определяет подстановку выражений (в данном случае констант) для переменных; подстановка применяется ко всем переменным в формуле:
"wor" с "Hello world" c= ("Hello world" = tl || t2) л ("wor" с tl)
Теперь мы должны показать, что:
("Hello world" = t1|| t2) л ("wor" с tl)
является истинным, и это ведет к новому соответствию образцов, а именно попытке установить соответствие "Hello world" с tl || t2. Здесь, конечно, может быть много соответствий, что приведет к поиску. Например, машина вывода может допускать, чтобы tl указывало на "Не", a t2 указывало на "Но world"; эти подстановки затем проводятся во всем вычислении.
Знак «: — » обозначает импликацию, а переменные должны начинаться с прописных букв. Когда задана цель:
?- substring ("wor", "Hello world").
вычисление пытается унифицировать ее с головой формулы; если это удается сделать, цель заменяется последовательностью элементарных формул (также называемых целями):
?- concat ("Hello world", T1,12), substring ("wor", T1).
Цель, которая получается в результате, может состоять из боле? чем одной элементарной формулы; машина вывода должна теперь выбрать одну из них, чтобы продолжить поиск решения. По правилу вычисления языка Prolog машина вывода всегда выбирает крайнюю левую элементарную формулу. В данном примере правило вычисления требует, чтобы concat было выбрано перед рекурсивным вызовом substring.
Головы нескольких формул могут соответствовать выбранной элементарной формуле, и машина вывода должна выбрать одну из них, чтобы попытаться сделать унификацию. Правило поиска в языке Prolog определяет, что формулы выбираются в том порядке, в котором они появляются в тексте программы.
При попытке установить соответствие целевой
При попытке установить соответствие целевой формулы с формулами процедуры substring правило поиска требует, чтобы сначала была выбрана истинная substring (Т,Т), затем вторая формула с substring (S, T1), и, только если она не выполняется, третья формула с substring (S, T2). ,
Основанием для этих, по-видимому, произвольных требований, послужило то, что они дают возможность реализовать язык Prolog на стековой архитектуре точно так же, как языки С и Ada, и сделать большинство вычислений в языке Prolog столь же эффективными, как и в процедурных языках. Вычисление выполняется перебором с откатами (backtracking). В приведенном выше примере:
?- concat ("Hello world", Т1, Т2), substring ("wor", T1).
предположим, что вычисление выбрало для concat подстановку
["Н" -»tl, "ello world" -> t2]
Теперь делается попытка доказать substring ("wor", "H"), которая, очевидно, не выполняется. Вычисление делает откат и пытается найти другое доказательство concat с другой подстановкой. Все данные, необходимые для вычисления substring ("wor", "Н"), можно отбросить после отката. Таким образом, правило вычисления в языке Prolog естественно и эффективно реализуется на стеке.
Чтобы еще улучшить эффективность программ, написанных на языке Prolog, в язык включена возможность, названная обрезанием (cut обозначается «!»), которая позволяет задать указание машине вывода воздержаться от поиска части пространства возможных решений. Именно программист должен гарантировать, что никакие возможные решения не «обрезаны». Например, предположим, что мы пытаемся проанализировать арифметическое выражение, которое определено как два терма, разделенных знаком операции:
expression (T1, OP, T2):- term (T1), operator (OP), !, term (T2).
operator ('+').
operator ('-').
operator ('*').
operator ('/').
и что цель — expression (n, '+', 27).
одним из операторов, поэтому цель
Очевидно, что и п и 27 являются термами, а '+' — одним из операторов, поэтому цель выполняется. Если, однако, в качестве цели задать expression (n,'+', '>'), то вычисление при отсутствии обрезания продолжится следующим образом:
n — терм
'+' соответствует operator ('+')
'>' —нетерм
'+' не соответствует operator('-')
'+' не соответствует operator ('*')
'+' не соответствует operator ('/')
Машина вывода делает откат и пытается доказать operator (OP) другими способами в надежде, что другое соответствие позволит также доказать term (T2). Конечно, программист знает, что это безнадежно: обрезание приводит к тому, что вся формула для expression дает неуспех, если неуспех происходит после того, как будет пройдено обрезание. Конечно, обрезание уводит язык Prolog еще дальше от идеального декларативного логического программирования, но обрезание активно используют на практике для улучшения эффективности программы.
Нелогические формулы
Для практического применения в язык Prolog включены свойства, которые не имеют никакого отношения к логическому программированию. По определению операторы вывода не имеют никакого логического значения в вычислении, поскольку их результат относится только к некоторой среде за пределами программы. Однако операторы вывода необходимы при написании программ, которые открывают файлы, отображают символы на экране и т. п.
Другая область, в которой язык Prolog отходит от чистого логического программирования, — численные вычисления. Конечно, в логике можно определить сложение; фактически, это единственный способ определить сложение строго:
N + 0 = N
N + s (М) = s (К) <= N + М = К
О — это числовой ноль, a s(N) — выражение для числа, следующего за N, так, например, s(s(s(0))) — выражение для числа 3. Формулы определяют «+», используя два правила: 1) число плюс ноль — это само число, и 2) N плюс следующее за М — это следующее за N + М. Очевидно, было бы чрезвычайно утомительно писать и неэффективно выполнять логическую версию для 555 + 777.
и создается новая переменная Var
Prolog включает элементарную формулу:
Var is Expression
Вычисляется значение Expression, и создается новая переменная Var с этим значением. Обратите внимание, что это не присваивание; переменной нельзя присвоить значение еще раз, ее только можно будет использовать позднее как аргумент в какой-нибудь элементарной формуле.
Вычисление выражения и присваивание вновь созданной переменной можно использовать для моделирования циклов:
loop (0).
loop (N) :-
proc,
N1 isN-1,
loop(N1).
Следующая цель выполнит proc десять раз:
?-loop (10).
Аргумент является переменной, которая используется как индекс. Первая формула — базовый случай рекурсии: когда индекс равен нулю, больше ничего делать не нужно. В противном случае выполняется процедура proc, создается новая переменная N1 со значениями N-1, которая используется как аргумент для рекурсивного вызова loop. Унификация создает новую переменную для каждого использования второй формулы loop. Нельзя сказать, что это слишком неэффективно, потому что это можно выполнить в стеке. К тому же многие компиляторы Prolog могут делать оптимизацию хвостовой рекурсии, т. е. заменять рекурсию обычной итерацией, если рекурсивный вызов является последним оператором в процедуре.
Причина того, что использование is — нелогическое, состоит в том, что оно не симметрично, т. е. вы не можете написать:
28 is V1 * V2
или даже:
28 is V1*7
где V1 и V2 — переменные, которые еще не получили своих значений. Для этого потребовалось бы знать семантику арифметики (как разлагать на множите ли и делить целые числа), в то время как унификация устанавливает только синтаксическое соответствие термов.
База данных на языке Prolog
Нет никаких других ограничений на количество формул, которые может содержать программа на языке Prolog, кроме ограничений, связанных с размером памяти компьютера. В частности, нет ограничения на количество фактов, которые можно включить в программу, поэтому набор фактов на языке Prolog может выполнять функцию таблицы в базе данных:
Обычные цели языка Prolog могут
customer(1, "Jonathan"). /* клиент(Идент_клиента, Имя) */
customer(2, "Marilyn"),
customer^, "Robert").
salesperson 101, "Sharon"). /* продавец(Идент_продавца, Имя) */
salesperson 102, "Betty").
salesperson 103, "Martin").
order(103, 3, "Jaguar"). /*заказ(Идент_продавца,
order(101, 1, "Volvo"). Идент_клиента, товар)*/
order(102, 2, "Volvo").
order(103, 1, "Buick").
Обычные цели языка Prolog могут интерпретироваться как запросы к базе данных. Например:
?- salesperson(SalesJD, "Sharon"), /* ID Шэрон */
order(SalesJD, CustJD, "Volvo"), /* Заказ Volvo */
customer(CustJD, Name). /* Клиент заказа */
означает следующее: «Кому Шэрон продала Volvo?». Если запрос успешный, переменная Name получит значение имени одного из клиентов. В противном случае мы можем заключить, что Шэрон никому Volvo не продавала.
Сложные запросы базы данных становятся простыми целями в языке Prolog. Например: «Есть ли клиент, которому продавали автомобиль и Шэрон, и Мартин?»:
?- salesperson(ID1,"Sharon"), /* ID Шэрон */
salesperson(ID2, "Martin"), /* ID Мартина */
order(ID1, CustJD, _), /* ID клиента Шэрон */
order(ID2, CustJD, _). /* ID клиента Мартина */
Поскольку переменная CustJD является общей для двух элементарных формул, цель может быть истинной только, когда один и тот же клиент делал заказ у каждого из продавцов.
Является ли язык Prolog реальной альтернативой специализированному программному обеспечению баз данных? Реализация списков фактов вполне эффективна и может легко отвечать на запросы для таблиц из тысяч записей.
если ваши таблицы содержат десятки
Однако, если ваши таблицы содержат десятки тысяч записей, необходимы более сложные алгоритмы поиска. К тому же, если ваша база данных предназначена для непрограммистов, необходим соответствующий интерфейс пользователя, и в этом случае ваша реализация языка Prolog может и не оказаться подходящим языком программирования.
Важно подчеркнуть, что «это не было сделано профессионалами», т. е. мы не вводили ни новый язык, ни понятия базы данных; это было всего лишь обычное программирование на языке Prolog. Любой программист может создавать небольшие базы данных, просто перечисляя факты, а затем в любой момент выдавать запросы.
Динамические базы данных
Если все наборы фактов, существуют с самого начала программы на языке Prolog, запросы совершенно декларативны: они только просят о заключении, основанном на ряде предположений (фактов). Однако язык Prolog включает нелогическое средство, с помощью- которого можно менять базу данных в процессе вывода. Элементарная формула assert(F) всегда истинна как логическая формула, но в качестве побочного эффекта она добавляет факт F к базе данных; точно так же retract(F) удаляет факт F:
?- assert(order( 102, 2, "Peugeot")), /* Бетти продает автомобиль'*/
assert(order(103,1 , "BMW")), /* Мартин продает автомобиль */
assert(order(102, 1, "Toyota")), /* Бетти продает автомобиль*/
assert(order(102, 3, "Fiat")), /* Бетти продает автомобиль */
retract(salesperson(101, "Sharon")). /* Уволить Шэрон! */
С помощью изменений базы данных можно в языке Prolog смоделировать оператор присваивания. Предположим, что факт count(O) существует в программе, тогда:
increment :-
N1 is N +1, /* Новая переменная с новым значением */
retract(count(N)), /* Стереть старое значение */
Ни одна из трех элементарных
assert(count(N1)). /* Сохранить новое значение */
Ни одна из трех элементарных формул не является логической!
Вспомните, что присваивание используется, чтобы записать состояние вычисления. Таким образом, альтернатива моделированию присваивания — внести каждую переменную состояния как дополнительный аргумент в формулы, которые могут стать и сложными, и запутанными. На практике в программах на языке Prolog допустимо использовать нелогические операции с базой данных как для того, чтобы реализовать динамические базы данных, так и для того, чтобы улучшить читаемость программы.
Сортировка в языке Prolog
В качестве примера соотношения между описательным и процедурным взглядами на логическую программу мы обсудим программы сортировки на языке Prolog. Мы ограничимся сортировкой списков целых чисел. Обозначения: [Head]Tail] является списком, первый элемент которого — Head, а остальные элементы образуют список Tail. [] обозначает пустой список.
Сортировка в логическом программировании вполне тривиальна, потому нам нужно только описать смысл того, что список L2 является отсортированной версией списка L1. Это означает, что L2 представляет собой перестановку (permutation) всех элементов L1 при условии, что элементы упорядочены (ordered):
sort(L1, L2):- permutation(L1, L2), ordered(L2).
где формулы в теле процедуры определены как:
permutation([], []).
permutation(L, [X | Tail]) :-
append(Left_Part, [X | Right_Part], L),
append(Left_Part, Right_Part, ShortJJst),
permutation(Short__List, Tail).
ordered([]).
ordered([Single]).
ordered([First, Second | Tail]) :-
First =< Second,
ordered([Second | Tail]).
Прочитаем их описательно:
• Пустой список является перестановкой пустого списка. Перестановка непустого списка является разделением списка на элемент X и две части Left_Part и Right_Part, так, что X добавляется в начало перестановки конкатенации двух частей.
с не более чем одним
Например:
permutation([7,2,9,3], [91Tail])
если Tail является перестановкой [7,2,3].
• Список с не более чем одним элементом упорядочен. Список упорядочен, если первые два элемента упорядочены, и список, состоящий из всех элементов, кроме первого, также упорядочен.
С точки зрения процедуры это не самая эффективная программа сортировки; действительно, ее обычно называют медленной сортировкой! Она просто перебирает (генерирует) все перестановки списка чисел, пока не найдет отсортированный список. Однако также просто написать описательную версию более эффективных алгоритмов сортировки типа сортировки вставкой, который мы рассмотрели на языке ML в предыдущей главе:
insertion_sort([], []).
insertion_sort([Head | Tail], List) :-
insertion_sort(Tail, Tail _1),
insert_element(Head, Tail_1, List).
insert_element(X, [], [X]).
insert_element(X, [Head | Tail], [X, Head | Tail]) :-
X=<Head.
insert_element(X, [Head Tail], [Head Tail_1]) :-
insert_element(X, Tail, Tail_1).
С процедурной точки зрения программа вполне эффективна, потому что она выполняет сортировку, непосредственно манипулируя подсписками, избегая бесцельного поиска. Как и в функциональном программировании, здесь нет никаких индексов, циклов и явных указателей, и алгоритм легко обобщается для сортировки других объектов.
Типизация и «неуспех»
В языке Prolog нет статического контроля соответствия типов. К сожалению, реакция машины вывода языка Prolog на ошибки, связанные с типом переменных, может вызывать серьезные затруднения для программиста. Предположим, что мы пишем процедуру для вычисления длины списка:
length([], 0). /* Длина пустого списка равна 0 */
length([Head | Tail], N) : - /* Длина списка равна */
length(Tail, N1), /* длине Tail */
N is N1+1. /* плюс 1*/
и случайно вызываем ее с целочисленным значением вместо списка:
Это не запрещено, потому что
?- length(5, Len).
Это не запрещено, потому что вполне возможно, что определение length содержит дополнительную нужную для отождествления формулу.
Машина вывода при вызове lenght в качестве реакции просто даст неуспех, что совсем не то, что вы ожидали. A length была вызвана внутри некоторой другой формулы р, и неуспех length приведет к.неуспеху р (чего вы также не ожидали), и так далее назад по цепочке вызовов. Результатом будут неуправляемые откаты, которые в конце концов приведут к неуспеху первоначальной цели при отсутствии какой-либо очевидной причины. Поиск таких
ошибок — очень трудный процесс трассировки вызовов шаг за шагом, пока ошибка не будет диагностирована.
По этой причине некоторые диалекты языка Prolog типизированы и требуют, чтобы вы объявили, что аргумент является или целым числом, или списком, или некоторым типом, определенным программистом. В типизированном языке Prolog вышеупомянутый вызов был бы ошибкой компиляции. В таких диалектах мы снова встречаем привычный компромисс: обнаружение ошибок во время компиляции за счет меньшей гибкости.
17.4. Более сложные понятия логического программирования
Успех языка Prolog стимулировал появление других языков логического программирования. Многие языки попытались объединить преимущества логического программирования с другими парадигмами программирования типа объектно-ориентированного и функционального программирования. Вероятно, наибольшие усилия были вложены в попытки использовать параллелизм, свойственный логическому программированию. Вспомните, что логическая программа состоит из последовательности формул:
t=>t
(t = tl || t2)^(SCtl)=>(S=>t)
(t = tl || 12) ^ (s с t2) => (s => t)
Язык Prolog вычисляет каждую цель последовательно слева направо, но цели можно вычислять и одновременно. Это называется и-параллелизмом из-за конъюнкции, которая соединяет формулы цели. Сопоставляя цели с головами формул программы, язык Prolog проверяет каждую формулу последовательно в том порядке, в котором она встречается в тексте, но можно проверять формулы и одновременно.
потому что каждая цель должна
Это называется или-параллелизмом, потому что каждая цель должна соответствовать первой или второй формуле, и т. д.
При создании параллельных логических языков возникают трудности. Проблема м-параллелизма — это проблема синхронизации: когда одна переменная появляется в двух различных целях, подобно tl в примере, фактически только одна цель может конкретизировать переменную (записывать в нее), и это должно заблокировать другие цели от чтения переменной прежде, чем будет выполнена запись. В мям-параллелизме несколько процессов выполняют параллельный поиск решения, один для каждой формулы процедуры; когда решение найдено, должны быть выполнены некоторые действия, чтобы сообщить этот факт другим процессам, и они могли бы завершить свои поиски.
Много усилий также прилагалось для интеграции функционального и логического программирования. Существует очень близкая связь между математикой функций и логикой, потому что:
y = f(xb
...,х„)
Основные различия между двумя концепциями программирования следующие:
1. Логическое программирование использует (двунаправленную) унификацию, что сильнее (однонаправленного) сопоставления с образцом, используемого в функциональном программировании.
2. Функциональные программы являются однонаправленными в том смысле, что, получив все аргументы, программа возвращает значение. В логических программах любой из аргументов цели может остаться неопределенным, и ответственность за его конкретизацию (instantiating) в соответствии с ответом лежит на унификации.
3. Логическое программирование базируется на машине вывода, которая автоматически ищет ответы.
4. Функциональное программирование оперирует с объектами более высокого уровня абстракции, поскольку функции и типы можно использовать и как данные, в то время как логическое программирование более или менее ограничено формулами на обычных типах данных.
5. Точно так же средства высокого порядка в функциональных языках программирования естественно обобщаются на модули, в то время как логические языки программирования обычно «неструктурированы».
ние отождествления от простой синтаксической
Новая область исследования в логическом программировании — расшире ние отождествления от простой синтаксической унификации к включению семантической информации. Например, если цель определяет 4 < х < 8 и голова формулы определяет 6 < х < 10, то мы можем заключить, что 6 s х < 8 и что х = 6 или х = 7. Языки, которые включают семантическую информацию при отождествлении, называются ограниченными (constraint) логическими языками программирования, потому что значения ограничиваются уравнениями. Ограниченные логические языки программирования должны базироваться на эффективных алгоритмах для решения уравнений.
Продвижение в этом направлении открывает новые перспективы повышения как уровня абстракции, так и эффективности логических языков программирования.
17.5. Упражнения
1. Вычислите 3 + 4, используя логическое определение сложения.
2. Что произойдет, если программа loop вызвана с целью 1оор(-1)? Как можно исправить программу?
3. Напишите программу, которая не завершается из-за конкретного правила вычисления, принятого в языке Prolog . Напишите программу, которая не завершается из-за правила поиска.
4. По правилам языка Prolog поиск решений осуществляется сначала вглубь (depth-first search), поскольку крайняя левая формула неоднократно выбирается даже после того, как она была заменена. Также можно делать поиск сначала в ширину (breath-first search), выбирая формулы последовательно слева направо и возвращаясь к крайней левой формуле, только когда все другие уже выбраны. Как влияет это правило на успех вычисления?
5. Напишите цель на языке Prolog для следующего запроса:
Есть ли тип автомобиля, который был продан Шэрон, но не Бетти?
Если да, какой это был автомобиль?
6. Изучите встроенную формулу языка Prolog findall и покажите, как она может ответить на следующие запросы:
Сколько автомобилей продал Мартин?
Продал ли Мартин больше автомобилей, чем Шэрон?
Напишите программу на языке Prolog
7. Напишите программу на языке Prolog для конкатенации списков и сравните ее с программой на языке ML. Выполните программу на языке Prolog в различных «направлениях».
8. Как можно изменить процедуру языка Prolog, чтобы она улавливала несоответствия типов и выдавала сообщение об ошибке?
Какие типы логических программ извлекли бы выгоду из м-параллелиз-ма, а какие — из м/ш-параллелизма?
Глава 18
Java
Java является и языком программирования, и моделью для разработки программ для сетей. Мы начнем обсуждение с описания модели Java, чтобы показать, что модель не зависит от языка. Язык интересен сам по себе, но повышенный интерес к Java вызван больше моделью, чем свойствами языка.
18.1. Модель Java
Можно написать компилятор для языка Java точно так же, как и для любого другого процедурного объектно-ориентированного языка. Модель Java, однако, базируется на концепции интерпретатора (см. рис. 3.2, приведенный в измененной форме как рис. 18.1), подобного интерпретаторам для языка Pascal, которые мы обсуждали в разделе 3.10.

В Java стрелка от J-кода к интерпретатору J-кода представляет не просто поток данных между компонентами среды разработки программного обеспечения. Вместо этого J-код может быть упакован в так называемый аплет (applet), который может быть передан по компьютерной системе сети. Принимающий компьютер выполняет J-код, используя интерпретатор, называющийся виртуальной Java машиной (Java Virtual Machine — JVM). JVM обычно встроена внутрь браузера сети, который является программой поиска и отображения информации, получаемой по сети. Когда браузер определяет, что был получен аплет, он вызывает JVM, чтобы выполнить J-код. Кроме того, модель Java включает стандартные библиотеки для графических интерфейсов пользователя, мультимедиа и сетевой связи, которые отображаются каждой реализацией JVM на средства основной операционной системы.
Это является значительным расширением концепции
Это является значительным расширением концепции виртуальной машины по сравнению с простым вычислением Р-кода для языка Pascal.
Обратите внимание, что также можно написать обычную программу на Java, которая называется приложением. Приложение не подчиняется ограничениям по защите данных, рассматриваемым ниже. К сожалению, имеются несколько огорчающих различий между программированием аплета и приложения.
Проблема эффективности
Слишком хорошо, чтобы быть правдой? Конечно. Модель Java страдает от тех же самых проблем эффективности, которые присущи любой модели, основанной на интерпретации абстрактного машинного кода. Для относительно простых программ, выполняющихся на мощных персональных компьютерах и рабочих станциях, это не вызовет серьезных проблем, но производительность может установить ограничение на применимость модели Java.
Одно из решений состоит в том, чтобы включить в браузер на получающей стороне компилятор, который переводит абстрактный J-код в машинный код принимающего компьютера. Фактически, компьютер может выполнять этот перевод одновременно или почти одновременно с приемом J-кода; это называется компиляцией «налету». В худшем случае скорость работы возрастет при втором выполнении аплета, который вы загрузили.
Однако это решение — только частичное. Не очень практично встраивать сложный оптимизирующий компилятор внутрь каждого браузера для каждой комбинации компьютера и операционной системы. Тем не менее, для многих типов прикладных программ модель Java вполне подойдет для разработки переносимого программного обеспечения.
Проблема безопасности
Предположим, что вы загружаете аплет и выполняете его на своем компьютере. Откуда вы знаете, что он не собирается затереть ваш жесткий диск? Оценив существенный ущерб от компьютерных вирусов, злонамеренно внедренных во вполне хорошие в других отношениях программы, вы можете понять, как опасно загружать произвольные программы, взятые с удаленного пункта сети.
Модель Java использует несколько стратегий
Модель Java использует несколько стратегий устранения (или по крайней мере уменьшения!) возможности того, что аплет, пришедший по сети, повредит программное обеспечение и данные на принявшем его компьютере:
• Строгий контроль соответствия типов как в языке Ada. Идея состоит в том, чтобы устранить случайное или преднамеренное повреждение данных, вызванное выходом индексов за границы массива, произвольными или повисшими указателями и т. д. Мы рассмотрим этот вопрос подробно в следующих разделах.
• Проверка J-кода. Интерпретатор на принимающем компьютере проверяет, действительно ли поток байтов, полученных с удаленного компьютера, состоит из допустимых инструкций J-кода. Это гарантирует, что реально выполняется семантика безопасности модели и что не удастся «обмануть» интерпретатор и причинить вред.
• Ограничения на аплет. Аплету не разрешается выполнять некоторые операции на получающем компьютере, например запись или удаление файлов. Это наиболее проблематичный аспект модели безопасности, потому что хотелось бы писать аплеты, которые могут делать все, что может делать обычная программа.
Ясно, что успех Java зависит от того, является ли модель безопасности достаточно строгой, чтобы предотвратить злонамеренное использование JVM, в то же самое время сохраняя достаточно возможностей для создания полезных программ.
Независимость модели от языка
Проницательный читатель может заметить, что в предыдущем разделе не было ссылок на язык программирования Java! Это сделано специально, потому что модель Java является и эффективной, и полезной, даже если исходный текст аплетов написан на каком-нибудь другом языке. Например, существуют компиляторы, которые переводят Ada95 в J-Код3.
Однако язык Java был разработан вместе с JVM, и семантика языка почти полностью соответствует возможностям модели.
18.2. Язык Java
На первый взгляд синтаксис и семантика языка Java аналогичны принятым в языке C++.
с языком С, Java отказывается
Однако в то время как C++ сохраняет почти полную совместимость с языком С, Java отказывается от совместимости ради устранения трудностей, связанных с проблематичными конструкциями языка С. Несмотря на внешнее сходство, языки Java и C++ весьма различны, и программу на C++ не так легко перенести на Java.
В основном языки похожи в следующих областях:
• Элементарные типы данных, выражения и управляющие операторы.
• Функции и параметры.
• Объявления класса, члены класса и достижимость.
• Наследование и динамический полиморфизм.
• Исключения.
В следующих разделах обсуждается пять областей, где проект Java существенно отличается от C++: семантика ссылки, полиморфные структуры данных, инкапсуляция, параллелизм и библиотеки. В упражнениях мы просим вас изучить другие различия между языками.
18.3. Семантика ссылки
Возможно, наихудшее свойство языка С (и C++) — неограниченное и чрезмерное использование указателей. Причем операции с указателями не только трудны для понимания, они чрезвычайно предрасположены к ошибкам, как описано в гл. 8. Ситуация в языке Ada намного лучше, потому что строгий контроль соответствия типов и уровни доступа гарантируют, что использование указателей не приведет к разрушению системы типов, однако структуры данных по-прежнему должны формироваться с помощью указателей.
Язык Java (подобно Eifiel и Smalltalk) использует семантику ссылки вместо семантики значения.
При объявлении переменной непримитивного типа память не выделяется; вместо этого выделяется неявный указатель. Чтобы реально выделить память для переменной, необходим второй шаг. Покажем теперь, как семантика ссылки работает в языке Java.
Массивы
Если вы объявляете массив в языке С, то выделяется память, которую вы запросили (см. рис. 18.2а):
|
C |
в то время как в языке Java вы получаете только указатель, который может использоваться для обращений к массиву (см.
Для размещения массива требуется дополнительная
рис. 18.26):
|
Java |
Для размещения массива требуется дополнительная команда (см. рис. 18.2 в):
a Java = new int[10];
|
Java |
|
Java |
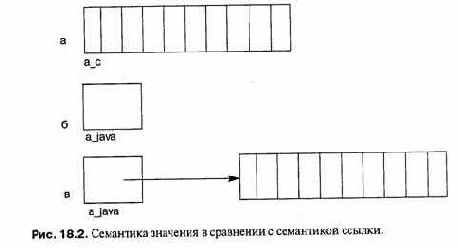
Если вы сравните рис. 18.2 с рис. 8.4, вы увидите, что массивы в Java скорее подобны структурам, определенным в языке C++ как int *a, а не как int a []. Различие заключается в том, что указатель является неявным, поэтому вы не должны заботиться об операциях с указателями или о выделении памяти. К тому же, в случае массива, переменная будет дескриптором массива (см. рис. 5.4), что дает возможность проверять границы при обращениях к массиву.
Отметим, что синтаксис Java проще читается, чем синтаксис C++: a_java is of type int [], что означает «целочисленный массив»; в языке C++ тип компонентов int и указание «масивности» [10] располагаются по разные стороны от имени переменной.
При использовании семантики ссылки разыменование указателя является неявным, поэтому после того, как массив создан, вы обращаетесь к нему как обычно:
for (i = 1; i< 10;i++)
|
Java |
Конечно, косвенный доступ может быть значительно менее эффективен, чем прямой, если его не оптимизирует компилятор.
Отметим, что выделение памяти для объекта и присваивание его переменной могут быть выполнены в любом операторе, в результате чего появляется следующая возможность:
|
Java |
…
a_Java = new int[20];
Переменная a_ Java, которая указывала на массив из десяти элементов, теперь указывает на массив из двадцати элементов, и исходный массив становится «мусором» (см. рис. 8.7). Согласно модели Java сборщик мусора должен находиться внутри JVM.
Динамические структуры данных
Как можно создавать списки и деревья без указателей?! Объявления для связанных списков в языках C++ и Ada, описанные в разделе 8.2, казалось бы, показывали, что нам нужен указательный тип для описания типа следующего поля next:
в Java каждый объект непримитивного
typedef struct node *Ptr;
|
C |
int data;
Ptr next;
} node;
Но в Java каждый объект непримитивного типа автоматически является указателем
class Node {
|
Java |
Node next;
}
Поле next — это просто указатель на узел, а не сам узел, поэтому в объявлении нет никакой цикличности. Объявление списка — это просто:
|
Java |
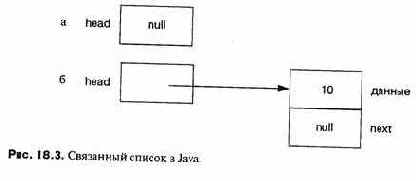
Этот оператор создает указатель переменной с нулевым значением (см. рис. 18.3,а). Подразумевая, что имеется соответствующий конструктор (см. раздел 15.3) для Node, следующий оператор создает узел в головной части списка (см. рис. 18.3,6):
|
Java |
Проверка равенства и присваивание
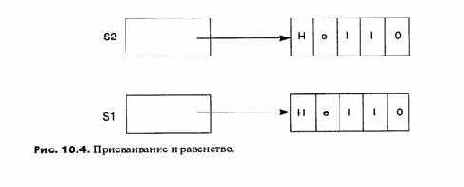
Поведение операторов присваивания и проверки равенства в языках с семантикой ссылки может оказаться неожиданным для программистов, которые работали на языке с семантикой значения. Рассмотрим объявления Java:
|
Java |
String s2 = new String("Hello");
В результате получается структура данных, показанная на рис. 18.4. Теперь предположим, что мы сравниваем строковые переменные:
|
Java |
else System.out.println("Not equal");
программа напечатает Not equal (He равно)! Причина этого хорошо видна из рис. 18.4: переменные являются указателями с разными значениями, и тот факт, что они указывают на равные массивы, не имеет значения. Точно так же, если мы присваиваем одну строку другой s1 = s2, будут присвоены указатели, но никакого копирования значений при этом не будет. В этом случае, конечно, s1 == s2 будет истинно. Java делает различие между мелкими копированием и проверкой равенства и глубокими копированием и сравнением. Последние объявлены в классе Object — общем классе-прародителе — и названы clone и eguals. Предопределенный класс String, например, переопределяет эти операции, поэтому s1.equals(s2) будет истинно.
определить эти операции, чтобы создать
Вы можете также пере определить эти операции, чтобы создать глубокие операции для своих классов.
Подведем итог использования семантики ссылки в Java:
• Можно безопасно управлять гибкими структурами данных.
• Программирование упрощается, потому что не нужны явные указатели.
• Есть определенные издержки, связанные с косвенностью доступа к структурам данных.
18.4. Полиморфные структуры данных
В языках Ada и C++ есть два пути построения полиморфных структур данных: generics в Ada и templates в C++ для полиморфизма на этапе компиляции, и типы в Ada и указатели/ссылки на классы для полиморфизма на CW-этапе выполнения. Преимущество generies/templates состоит в том, что структура данных фиксируется при создании экземпляра во время компиляции; это позволяет как генерировать более эффективный код, так и более экономно распределять память для структур данных.
В языке Java решено реализовать полиморфизм только на этапе выполнения. Как и в языках Smalltalk и Eiffel, считается, что каждый класс в Java порождается из корневого класса, названного Object. Это означает, что значение любого непримитивного типа8
может быть присвоено объекту типа Object. (Конечно, это работает благодаря семантике ссылки.)
Чтобы создать связанный список, класс Node должен быть сначала определен как содержащий (указатель на) Object. Класс списка тогда должен содержать методы вставки и поиска значения типа Object:
|
Java |
Object data;
Node next;
}
class List {
|
Java |
void Put(Object data) {...};
Object Get() {...};
}
Если L является объектом типа List (Список), и а является объектом типа Airplane_Data, то допустимо L.Put(a), потому что Airplane_Data порождено из Object. Когда значение выбирается из списка, оно должно быть приведено к соответствующему потомку Object:
если возвращенное значение не имеет
|
Java |
Конечно, если возвращенное значение не имеет тип Airplane_Data (или не порождено из этого типа), возникнет исключение.
Преимущество этой парадигмы состоит в том, что в Java очень просто писать обобщенные структуры данных, но по сравнению с generics/tem-plates имеются два недостатка: 1) дополнительные издержки семантики ссылки (даже для списка целых чисел!), и 2) опасность, что объект, размещенный не в той очереди, приведет при поиске к ошибке на этапе выполнения программы.
18.5. Инкапсуляция
В разделе 13.1 мы обсуждали тот факт, что в языке С нет специальной конструкции инкапсуляции, а в разделе 13.5 отметили, что операция разрешения области действия и конструкция namespace (пространство имен) в C++ уточняет грубое приближение языка С к проблеме видимости глобальных имен. Для совместимости в язык C++ также не была включена конструкция инкапсуляции; вместо этого сохраняется зависимость от «h»-файлов. В Ada есть конструкция пакета, которая поддерживает инкапсуляцию конструкций в модули (см. раздел 13.3), причем спецификации пакетов и их реализации (тела) могут компилироваться отдельно. Конструкции with позволяют разработчику программного обеспечения точно определить зависимости между модулями и использовать порожденные пакеты (кратко упомянутые в разделе 15.2) для разработки модульных структур с иерархической достижимостью.
Java содержит конструкцию инкапсуляции, названную пакетом (package), но, к сожалению, конструкция эта по духу ближе к пространству имен (namespace) в языке C++, чем к пакету Ada! Пакет является совокупностью классов:
package Airplane_Package;
public class Airplane_Data
|
Java |
int speed; // Доступно в пакете
private int mach_speed; // Доступно в классе
public void set_speed(int s) {...}; // Глобально доступно
Пакет может быть разделен на
public int get_speed() {...};
}
public class Airplane_Database
{
public void new_airplane(Airplane_Data a, int i)
{
if (a.speed > 1000) // Верно !
a.speed = a.mach_speed; // Ошибка !
}
private Airplane_Data[ ] database = new Airplane_Data[1000];
}
Пакет может быть разделен на несколько файлов, но файл может содержать классы только из одного пакета.
Спецификаторы public и private аналогичны принятым в языке C++: public (общий) означает, что элемент доступен за пределами класса, в то время как private (приватный) ограничивает достижимость для других членов класса. Если никакой спецификатор не задан, то элемент видим внутри пакета. В примере мы видим, что элемент int speed (скорость) класса Airplane_Data не имеет никакого спецификатора, поэтому к нему может обратиться оператор внутри класса Airplane_Database, так как два класса находятся в одном и том же пакете. Элемент mach_speed объявлен как private, поэтому он доступен только внутри класса Airplane_Data, в котором он объявлен.
Точно так же классы имеют спецификаторы достижимости. В примере оба класса объявлены как public, что означает, что другие пакеты могут обращаться к любому (public) элементу этих классов. Если класс объявлен как private, он доступен только внутри пакета. Например, мы могли бы объявить private класс Airplane_File, который использовался бы внутри пакета для записи в базу данных.
Пакеты играют важную роль в развитии программного обеспечения Java, потому что они позволяют группировать вместе связанные классы при сохранении явного контроля над внешним интерфейсом. Иерархическая библиотечная структура упрощает построение программных инструментальных средств.
Сравнение с другими языками
Пакеты Java служат для управления глобальными именами и достижимостью аналогично конструкции namespace в языке C++. При заданных в нашем примере объявлениях любая Java-программа может содержать:
и метода объявлены как public.
|
Java |
a.set_speed(100);
потому что имена класса и метода объявлены как public. He изучив полный исходный текст пакета, нельзя узнать, какие именно классы импортированы. Есть оператор import, который открывает пространство имен пакета, разрешая прямую видимость. Эта конструкция аналогична конструкциям using в C++ и uses Ada.
Основное различие между Java и Ada состоит в том, что в Ada спецификация пакета и тело пакета разделены. Это не только удобно для сокращения размера компиляций, но и является существенным фактором в разработке и поддержке больших программных систем. Спецификация пакета может быть заморожена, позволяя параллельно разрабатывать тело пакета и вести разработку других частей. В Java «интерфейс» пакета является просто совокупностью всех public-объявлений. Разработка больших систем на Java требует, чтобы программные инструментальные средства извлекали спецификации пакета и гарантировали совместимость спецификации и реализации.
Конструкция пакета дает Java одно главное преимущество перед C++. Пакеты сами используют соглашение об иерархических именах, которое позволяет компилятору и интерпретатору автоматически размещать классы. Например, стандартная библиотека содержит функцию, названную Java.lang.String.toUpperCase. Это интерпретируется точно так же, как операционная система интерпретирует расширенное имя файла: toUpperCase является функцией в пакете Java.lang.String. Библиотеки Java могут (но не обязаны) быть реализованы как иерархические каталоги, где каждая функция является файлом в каталоге для своего класса. Отметим, что иерархичность имен как бы вне языка; подпакет не имеет никаких особых привилегий при доступе к своему родителю. Здесь мы видим четкое отличие от пакетов-детей в Ada, которые имеют доступ к private-декларациям своих родителей при соблюдении правил, которые не позволяют экспортировать эти декларации.
в отличие от делегирования этих
18.6. Параллелизм
Ada — один из немногих языков, в которых поддержка параллелизма включена в сам язык, в отличие от делегирования этих функций операционной системе. Язык Java продолжает идеологию языка Ada в отношении переносимости параллельных программ вне зависимости от операционных систем. Важное применение параллелизма в Java — программирование серверов: каждый запрос клиента заставляет сервер порождать (spawn) новый процесс для выполнения этого запроса.
Параллельно исполняемые конструкции Java называются нитями (thread). Собственно в параллелизме нет никаких существенных различий между нитью и тем, что называют стандартным термином процесс; отличие состоит в реализации, ориентированной на выполнение многих нитей внутри одного и того же адресного пространства. Для разработки и анализа параллельных алгоритмов используется та же самая модель, что и в гл. 12 ,— чередующееся выполнение атомарных инструкций процессов.
Класс Java, который наследуется из класса Thread, объявляет только новый тип нить. Чтобы реально создать нить, нужно запросить память, а затем вызвать функцию start. В результате будет запущен метод run внутри нити:
class My_Thread extends Thread
{
public void run(){...}; // Вызывается функцией start
|
Java |
My_Thread t = new My_Thread(); // Создать нить
t.start(); //Активизировать нить
Одна нить может явно создавать, уничтожать, блокировать и разблокировать другую нить.
Эти конструкции аналогичны конструкциям в языке Ada, которые позволяют определить тип task (задача) и затем динамически создавать задачи.
Синхронизация
Java поддерживает форму синхронизации аналогично мониторам (см. раздел 12.4). Класс может содержать методы, специфицированные как synchronized (синхронный). С каждым таким объектом в классе связывается блокировка-пропускник (lock), которая гарантирует, что только одна нить в данный момент может выполнять синхронный метод в объекте.
Следующий пример показывает, как объявить
Следующий пример показывает, как объявить монитор для защиты разделяемого ресурса от одновременного использования несколькими нитями:
class Monitor
{
synchronized public void seize() throws InterruptedException
{
while (busy) wait();
|
Java |
}
synchronized public void release()
{
busy = false;
notify();
}
private boolean busy - false
}
Монитор использует булеву переменную, которая указывает состояние ресурса. Если две нити пытаются выполнить метод seize в мониторе, то только одна из них пройдет пропускник и выполнится. Эта нить установит переменную busy (занято) в состояние true (истина) и перейдет к использованию ресурса. По завершении метода пропускник откроется, и другая нить сможет выполнить метод seize. Теперь, однако, переменная busy будет иметь значение false (ложь). Вместо ненужных затрат времени ЦП на непрерывную проверку переменной нить предпочитает освободить ЦП с помощью запроса wait (ждать). Когда первая нить заканчивает использование разделяемого ресурса, она вызывает notify (уведомление), которое позволит ожидающей нити снова возобновить выполнение синхронного метода.
Конструкции Java для параллелизма достаточно просты. Нет ничего похожего на сложные рандеву Ada для прямой связи процесс-процесс. Даже по сравнению с защищенными объектами конструкции Java относительно слабы:
• Барьер защищенного объекта автоматически перевычисляется всякий раз, когда его значение может измениться; в Java нужно явно программировать циклы.
• Java предоставляет простую блокировку-пропускник для каждого объекта; в Ada заводится очередь для каждого входа. Таким образом, если несколько нитей Java ожидают входа в синхронный объект, вы не можете знать, какой из них будет запущен по notity, поэтому трудно программировать алгоритмы с гарантированно ограниченным временем ожидания.
В языках программирования очевидна тенденция
18.7. Библиотеки Java
В языках программирования очевидна тенденция сокращения «размеров» языка за счет расширения функциональности библиотек. Например, write — это оператор в языке Pascal со специальным синтаксисом, тогда как в Ada нет никаких операторов ввода/вывода; вместо этого ввод/вывод поддерживается пакетами стандартной библиотеки.
Стандартные библиотеки Ada предоставляют средства для ввода/вывода, обработки символов и строк, для вычисления математических функций и для системных интерфейсов. Язык C++ также поддерживает контейнерные классы, такие как стеки и очереди. Точно так же Java содержит базисные библиотеки, названные java.lang, java.util и java.io, которые являются частью спецификации языка.
В дополнение к спецификации языка имеется спецификация для интерфейса прикладного программирования (Application Programming Interface — API), который поддерживают все реализации Java. API состоит из трех библиотек: Java.applet, Java.awt и java.net.
Java.applet поддерживает создание и выполнение аплетов и создание прикладных программ мультимедиа.
Абстрактный комплект инструментальных оконных средств (Abstract Window Toolkit — AWT) — это библиотека для создания графических интерфейсов пользователя (GUI): окна, диалоговые окна и растровая графика.
Библиотека для сетевой связи (java.net) обеспечивает необходимый интерфейс для размещения и пересылки данных по сети.
Подведем итог:
• Java — переносимый объектно-ориентированный язык с семантикой ссылки.
• Интерфейс прикладного программирования API представляет переносимые библиотеки для поддержки развития программного обеспечения в сетях.
• Защита данных и безопасность встроены в язык и модель.
• Многие важные концепции Java заложены в языково-независимую машину JVM.
8.8. Упражнения
1. Задано арифметическое выражение:
(а + b) * (с + d)
Java определяет, что оно должно
Java определяет, что оно должно вычисляться слева направо, в то время как C++ и Ada позволяют компилятору вычислять подвыражения в любом порядке. Почему в Java более строгая спецификация?
2. Сравните конструкцию final в Java с константами в Ada.
3. Каково соотношение между спецификатором friend в C++ и конструкцией пакета в Java.
4. C++ использует спецификатор protected (защищенный), чтобы разрешить видимость членов в порожденных классах. Как именно конструкция пакета влияет на понятие защищенности в Java?
5. Сравните интерфейс в Java с многократным наследованием в C++.
6. Проанализируйте различия между пространством имен (namespace) в C++ и пакетом в Java, особенно относительно правил, касающихся файлов и вложенности.
7. Конструкция исключения в Java совершенно аналогична конструкции исключения в C++. Одно важное различие состоит в том, что метод Java должен объявить все исключения, которые он может породить. Обоснуйте это проектное решение и обсудите его последствия.
8. Сравните мониторы Java с классической конструкцией монитора.
9. Сравните возможности обработки строк в Ada95, C++ и Java.
10. Сравните операции clone и eguals в Java с этими операциями в языке Eiffel.
Ссылки
Официальное описание языка дается в:
James Gosling, Bill Joy and Guy Steele. The Java Language Specification. Addison-Wesley, 1997.
Sun Microsystems, Inc., где разработан язык Java, имеет Web-сайт, содержащий документацию и программное обеспечение: http://java.sun.com.
Приложение А
Где получить компиляторы
В течение многих лет студентам было сложно экспериментировать с языками программирования: компиляторы могут дорого стоить, и, возможно, не так просто убедить компьютерный центр установить и поддерживать программное обеспечение. Сегодня ситуация изменилась, и можно получить свободно распространяемые компиляторы для большинства, если не для всех, языков, которые мы обсудили.
Эти компиляторы предназначены для рабочих
Эти компиляторы предназначены для рабочих станций и даже персональных компьютеров, поэтому вы можете установить их дома или в своей лаборатории. Кроме того, они легко доступны через Internet.
Чтобы получать информацию относительно компиляторов для какого-либо языка, просмотрите файлы, называющиеся FAQ (Freguently Asked Questions — часто задаваемые вопросы). Их можно загрузить через анонимный ftp по адресу rtfm.mit.edu. В директории /pub/usenet находится (очень длинный) список поддиректорий; просмотрите comp.lang.x, где х — одно из ada, apl, с, с++, eiffel, icon, lisp, ml, prolog, Smalltalk и т.д. Переходите в одну и; этих поддиректорий и загружайте файлы, в которых есть символы FAQ. Эта файлы будут содержать списки доступных компиляторов языка, в частности те, которые можно загрузить, используя ftp. Хотя эти программы не представляют интереса как коммерческие пакеты, они вполне подходят для изучение и экспериментирования с языком.
В FAQ вы также найдете названия и адреса профессиональных ассоциаций, которые издают бюллетени и журналы, дающие современную информацию о языках.
C++
Свободно распространяемый компилятор для языка C++, называющийся дсс, был разработан в рамках проекта GNU компании Free Software Foundation. Более подробно см. FAQ в поддиректории gnu.g++.help на узле rtfm.mit.edu. Компилятор дсс был перенесен на большинство компьютеров включая персональные. Так как язык C++ все еще стандартизуется, дсс может отличаться от других компиляторов C++.
Ada 95
Нью-Йоркский университет разработал свободно распространяемый компилятор для языка Ada 95, названный gnat (GNU Ada Translator), gnat использует выходную часть дсс и перенесен почти на все компьютеры, которые поддерживают дсс. Современную информацию относительно ftp-сайтов для gnat см. в Ada FAQ; главный сайт находится в директории /pub/gnat в cs.nyu.edu. Там вы также найдете управляемую с помощью меню среду программирования для gnat, которая была разработана Университетом Джорджа Вашингтона.
это компилятор для подмножества языка
AdaS
Pascal- S — это компилятор для подмножества языка Pascal, который вырабатывает Р-код, являющийся машинным кодом для искусственной стековой машины. Включен также интерпретатор для Р-кода. Его автор разработал версию Pascal-S, названную AdaS, которая компилирует небольшое подмножество языка Ada. Исходный код AdaS можно найти в файле adasnn.zip (где пп — номер версии) в каталоге /languages/ada/crsware/pcdp в общей библиотеке языка Ada (PAL) на хосте wuarchive.wustl.edu.
AdaS не годится для серьезного программирования, но это превосходный инструмент для изучения методов реализации конструкций языка программирования, в частности управления стеком при вызовах подпрограмм и возвратах из них.
Приложение Б
Библиографический список
Обзоры по языкам программирования можно найти в:
Ellis Horowitz (ed.). Programming Languages: 4 Grand Tour. Springer Verlag, 1983.
Jean E. Sammet. Programming Languages: History and Fundamentals. Prentice Hall, 1969.
Richard L. Wexelblat. History of Programming Languages. Academic Press, 1981.
Особенно интересна книга Векселблата (Wexelblat); это запись конференции, где разработчики первых языков программирования описывают истоки и цели своей работы.
Превосходное введение в теорию вычисления (логику, машины Тьюринга, формальные языки и верификацию программ) можно найти в:
Zohar Manna. Mathematical Theory of Computation. McGraw-Hill, 1974.
В учебниках, рассчитанных на подготовленных учащихся обсуждается формальная семантика языков программирования:
Michael Marcotty and Henry Legrand. Programming Language Landscape: Syntax, Semantics and Implementation. SRA, Chicago, 1986.
Bertrand Meyer. Introduction to the Theory of Programming Languages. Prentice Hall International, 1991.
Alfred Aho, Ravi Sethi and
По компиляции смотрите следующие работы:
Alfred Aho, Ravi Sethi and Jeffrey D. Ullman. Compilers: Principles, Techniques and Tools. Addison-Wesley, 1986.
Charles N. Fisher and Richard J. LeBlanc. Grafting a Compiler. Benjamin Cummings, 1988.
Хорошим введением в объектно-ориентированное проектирование и программирование является:
Bertrand Meyer. Object-oriented Software Construction. Prentice Hall International, 1988.
Обратите внимание, что описанная там версия языка Eiffel устарела; если вы хотите изучить язык, смотрите современное описание:
Bertrand Meyer. Eiffel: the Language. Prentice Hall, 1992.
Конкретные языки программирования
Мы даже не будем пытаться перечислить множество учебников по языкам С, Ada и C++! Формальное описание языка Ada можно найти в справочном руководстве:
Ada 95Reference Manual. ANSI/ISO/IEC-8652:1995.
Справочное руководство очень формальное и требует тщательного изучения. Существует сопутствующий документ, называемый Объяснением (Rationale), в котором описана мотивация языковых конструкций и даны обширные примеры. Файлы, содержащие текст этих документов, можно бесплатно загрузить, как описано в Ada FAQ.
Стандарт языка С — ANS ХЗ.159-1989; международный стандарт — ISO/IEC 9899:1990. В настоящее время (конец 1995 г.), язык C++ еще не стандартизирован; информацию о том, как получить последний предлагаемый вариант стандарта языка C++, см. в FAQ. Более доступно справочное руководство:
Margaret A. Ellis and Bjarne Stroustrup. The Annotated C++ Reference Manual. Addison-Wesley, 1990 (reprinted 1994).
Следующая книга является «обоснованием» языка C++ и должна быть прочитана всеми серьезными студентами, изучающими этот язык:
Bjarne Stroustrup. The Design and Evolution of C++. Addison-Wesley, 1994.
Другие широко используемые объектно-ориентированные языки, которые стоит изучить, — Smalltalk и CLOS:
Adele Goldberg and David Robson. Smalltalk-80, the Language and its Implementation. Addison-Wesley, 1983.
Oriented Programming in Common Lisp:
Sonya E. Keene. Object- Oriented Programming in Common Lisp: a Programmer's Guide. Addison-Wesley, 1989.
В разделе 1.3 мы рекомендовали вам изучить один или несколько языков, основанных на конкретной структуре данных. Следующий список позволит вам начать это изучение:
Leonard Oilman and Alien J. Rose. APL: An Interactive Approach. John Wiley, 1984*.
Ralph E. Griswold and Madge T. Griswold. The Icon Programming Language (2nd Ed.). Prentice Hall, 1990.
J.T. Schwartz, R.B.K. Dewar, E. Dubinsky, and E. Schonberg. Programming with Sets: An Introduction to SETL Springer Verlag, 1986.
Patrick H.Winston and Berthold K.P.Horn. LISP (3rd Ed.). Addjson-Wesley, 1989.
Наконец, введение в языки и языковые понятия, которые были только кратце рассмотрены в этой книге, можно найти в:
М. Ben-Ari. Principles of Concurrent and Distributed Programming. Prentice Hall International, 1990.
Ivan Bratko. Prolog Programming for Artificial Intelligence (2nd Ed.). Addison-Wesley, 1990.
Chris Reade. Elements of Functional Programming. Addison-Wesley, 1989. Leon SterUng and Ehud Shapiro. The Art of Prolog. MIT Press, 1986. Jeffrey D. Ullman. Elements of ML Programming. Prentice Hall, 1994.
