Что послужило причиной такого решения
Что послужило причиной такого решения в языке Algol, и как оно было реализовано?
3
Более сложные
понятия
Глава 8
Указатели
8.1 . Указательные типы
Переменная — не более чем удобная нотация адресования ячейки памяти. Имя переменной является статическим и определено на этапе компиляции: разные имена относятся к разным ячейкам, и не существует способов «вычисления имени», кроме как в определенных видах контекстов, таких как индексирование массива. Значение указательного (ссылочного) типа (pointer type) — это адрес; указательная переменная (указатель) содержит адрес другой переменной или константы. Объект, на который указывают, называется указуемым или обозначаемым объектом (designated object). Указатели применяются скорее для вычислений над адресами ячеек, чем над их содержимым.
Следующий пример:
|
C |
int *ptr = &i;
породит структуру, показанную на рис. 8.1. Указатель ptr сам является переменной со своим собственным местом в памяти (284), но его содержимое — это адрес (320) другой переменной i.
Синтаксис объявления может ввести в заблуждение, потому что звездочка «*» по смыслу относится к типу int, а не к переменной ptr.
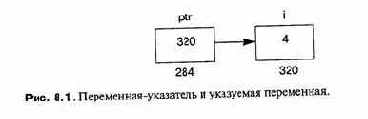
Объявление следует читать как: «ptr имеет указатель типа на int».. Унарная операция «&» возвращает адрес следующего за ней операнда.
К значению переменной i, конечно, можно получить доступ, просто использовав ее имя, например, как i + 1, но к нему также можно получить доступ путем разыменования (dereferencing)* указателя с помощью синтаксиса *ptr. Когда вы разыменовываете указатель, вы хотите увидеть не содержимое переменной-указателя ptr, а содержимое ячейки памяти, адрес которой содержится в ptr, то есть указуемый объект.
Типизированные указатели
В приведенном примере адреса записаны как целые числа, но адрес не является целым числом.
Форма записи адреса будет зависеть
Форма записи адреса будет зависеть от архитектуры компьютера. Например, компьютер Intel 8086 использует два 16-разрядных слова, которые объединяются при формировании 20-разрядного адреса. Разумно предположить, что все указатели представляются единообразно.
Однако в программировании полезнее и надежнее использовать типизированные указатели, которые объявляются, чтобы ссылаться на конкретный тип, такой как тип int в приведенном выше примере. Указуемый объект *ptr должен иметь целый тип, и после разыменования его можно использовать в любом контексте, в котором требуется число целого типа:
inta[10];
a[*ptr] = a[(*ptr) + 5]; /* Раскрытие и индексирование */
a[i] = 2 * *ptr; /* Раскрытие и умножение */
Важно делать различие между переменной-указателем и указуемым объектом и быть очень осторожными при присваивании или сравнении указателей:
int i1 = 10;
|
C |
int *ptr1 = &i1; /* ptrl указывает на i1 */
int *ptr2 = &i2; /* ptr2 указывает на i2 */
*ptr1 = *ptr2; /* Обе переменные имеют одно и то же значение */
if(ptr1 == ptr2)... /* «Ложь», разные указатели */
if (*ptr1 == *ptr2) /* «Истина», обозначенные объекты равны */
ptrl = ptr2; /* Оба указывает на i2 */
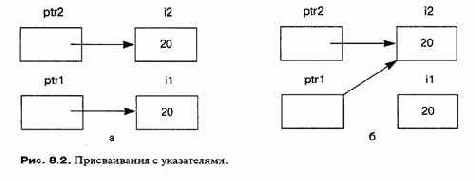
На рисунке 8.2а показаны переменные после первого оператора присваивания: благодаря раскрытию указателей происходит присваивание указуемых объектов и i1 получает значение 20. После выполнения второго оператора присваивания (над указателями, а не над указуемыми объектами) переменная i1 больше не является доступной через указатель, что показано на рис. 8.26.
Важно понимать различие между указателем-константой и указателем на константный указуемый объект.
константы не защищает указуемый объект
Создание указателя- константы не защищает указуемый объект от изменения:
inti1,i2;
int * const p1 = &i1; /* Указатель-константа */
const int * p2 = &i1; /* Указатель на константу */
const int * const p3 = &i1; /* Указатель-константа на константу */
p1 =&i2; /* Ошибка, указатель-константа */
*p1=5 /* Правильно, указуемый объект не является
константой */
р2 =&i2; /* Правильно, указатель не является
константой */
*р2 = 5; /* Ошибка, указуемый объект — константа */
рЗ =&i2; /* Ошибка, указатель-константа */
*рЗ = 5; /* Ошибка, указуемый объект — константа */
В языке С указатель на void является нетипизированным указателем. Любой указатель может быть неявно преобразован в указатель на void и обратно, хотя смешанное использование присваиваний типизированных указателей обычно будет сопровождаться предупреждающим сообщением. К счастью, в C++ контроль соответствия типов делается намного тщательнее. Типизированные указатели неявно могут быть преобразованы в указатели на void, но не обратно:
void *void_ptr; /* Нетипизированный указатель */
|
C |
char *char_ptr; /* Типизированный указатель */
void_ptr = int_ptr; /* Правильно */
С нет контроля соответствия типов,
char_ptr = void_ptr; /* Правильно в С, но ошибка в C++ */
char_ptr = int_ptr; /* Предупреждение в С, ошибка в C++ */
Поскольку в С нет контроля соответствия типов, указателю может быть присвоено произвольное выражение. Нет никакой гарантии, что указуемый объект имеет ожидаемый тип; фактически значение указателя могло бы даже не быть адресом в отведенной программе области памяти. В лучшем случае это приведет к аварийному сбою программы из-за неправильной адресации, и вы получите соответствующее сообщение от операционной системы. В худшем случае это может привести к разрушению данных операционной системы. Ошибки в указателях очень трудно выявлять при отладке, потому что сложно разобраться в абсолютных адресах, которые показывает отладчик. Решение состоит в более строгом контроле соответствия типов для указателей, как это делается в Ada и C++.
Синтаксис
Синтаксические конструкции, связанные с указателями, иногда могут вводить в заблуждение, поэтому очень важно хорошо их понимать. Раскрытие указателей, индексация массивов и выбор полей записей — это средства доступа к данным внутри структур данных. В языке Pascal синтаксис самый ясный: каждая из этих трех операций обозначается отдельным символом, который пишется после переменной. В следующем примере Ptr объявлен как указатель на массив записей с целочисленным полем:
type Rec_Type =
record
|
Pascal |
end;
type Array_Type = array[1 ..100] of Rec_Type;
type Ptr_Type = Array_Type;
Ptr: Ptr_Type;
Ptr (*Указатель на массив записей с целочисленным полем *)
Ptrt (*Массив записей с целочисленным полем *)
Ptrt [78] (*3апись с целочисленным полем *)
Ptrt [78].Field ("Целочисленное поле *)
В языке С символ раскрытия ссылки (*) является префиксным оператором, поэтому приведенный пример записывался бы так:
typedef struct {
Здесь необходимы круглые скобки, потому
int field;
|
C |
typedef Rec_Type Array_Type[ 100];
Array_Type *ptr;
ptr /* Указатель на массив записей с целочисленным полем */
*ptr /* Массив записей с целочисленным полем */
(*ptr)[78] /* Запись с целочисленным полем */
(*ptr)[78].field /* Целочисленное поле */
Здесь необходимы круглые скобки, потому что индексация массива имеет более высокий приоритет, чем раскрытие указателя. В сложной структуре данных это может внести путаницу при расшифровке декомпозиции, которая использует разыменование как префикс, а индексацию и выбор поля как постфикс. К счастью, наиболее часто используемая последовательность операций, в которой за разыменованием следует выбор поля, имеет специальный, простой синтаксис. Если ptr указывает на запись, то ptr->field — это краткая запись для (*ptr).field.
Синтаксис Ada основан на предположении, что за разыменованием почти всегда следует выбор поля, поэтому отдельная запись для разыменования не нужна. Вы не можете сказать, является R.Field просто выбором поля обычной записи с именем R, или R — это указатель на запись, который раскрывается перед выбором. Хотя такой подход и может привести к путанице, но он имеет то преимущество, что в структурах данных мы можем перейти от использования самих записей к использованию указателей на них без других изменений программы. В тех случаях, когда необходимо только разыменование, используется довольно неуклюжий синтаксис, как показывает вышеупомянутый пример на языке Ada:
type Rec_Type is
record
|
Ada |
end record;
type Array_Type is array( 1 .. 100) of Rec_Type;
type Ptr_Type is access Array_Type;
Ptr: Ptr_Type;
Ptr -- Указатель на массив записей с целочисленным полем
Ptr.all -- Массив записей с целочисленным полем
в Ada для обозначения указателей
Ptr.all[78] -- Запись с целочисленным полем
Ptr.all[78].Field --Целочисленное поле
Обратите внимание, что в Ada для обозначения указателей используется ключевое слово access, а не символ. Ключевое слово all используется в тех немногих случаях, когда требуется разыменование без выбора.
Реализация
Для косвенного обращения к данным через указатели требуется дополнительная команда в машинном коде. Давайте сравним прямой оператор присваивания с косвенным присваиванием, например:
|
C |
int*p = &i;
int *q = &j;
i=j; /* Прямое присваивание */
*p = *q; /* Косвенное присваивание */
Машинные команды для прямого присваивания:
|
C |
store R1,i
в то время как команды для косвенного присваивания:
load R1,&q Адрес (указуемого объекта)
|
C |
load R3,&p Адрес (указуемого объекта)
store R2,(R3) Сохранить в указуемом объекте
При косвенности неизбежны некоторые издержки, но обычно не серьезные, поскольку при неоднократном обращении к указуемому объекту оптимизатор может гарантировать, что указатель будет загружен только один раз. В операторе
p->right = p->left;
раз уж адрес р загружен в регистр, все последующие обращения могут воспользоваться этим регистром:
load R1 ,&p Адрес указуемого объекта
load R2,left(R1) Смещение от начала записи
store R2,right(R1) Смещение от начала записи
Потенциальным источником неэффективности при косвенном доступе к данным через указатели является размер самих указателей.
и Pascal, компьютеры обычно имели
В начале 1970-х годов, когда разрабатывались языки С и Pascal, компьютеры обычно имели только 16 Кбайт или 32 Кбайт оперативной памяти, и для адреса было достаточно 16 разрядов. Теперь, когда персональные компьютеры и рабочие станции имеют много мегабайтов памяти, указатели должны храниться в 32 разрядах. Кроме того, из-за механизмов управления памятью, основанных на кэше и страничной организации, произвольный доступ к данным через указатели может обойтись намного дороже, чем доступ к массивам, которые располагаются в непрерывной последовательности ячеек. Отсюда следует, что оптимизация структуры данных для повышения эффективности сильно зависит от системы, и ее никогда не следует делать до измерения времени выполнения с помощью профилировщика.
Типизированные указатели в Ada предоставляют одну возможность для оптимизации. Для набора указуемых объектов, связанных с конкретным типом доступа, т. е. для так называемой коллекции (collection), можно задать размер:
|
C |
for Node_Ptr'Storage_Size use 40_000;
Поскольку объем памяти, запрошенный для Node, меньше 64 Кбайт, указатели относительно начала блока могут храниться в 16 разрядах, при этом экономятся и место в структурах данных, и время центрального процессора для загрузки и сохранения указателей.
Указатели и алиасы в Ада 95
Указатель в языке С может использоваться для задания алиаса (альтернативного имени) обычной переменной:
|
C |
int *ptr = &i;
Алиасы бывают полезны; например, они могут использоваться для создания связанных структур во время компиляции. Так как в Ада 83 структуры, основанные на указателях, могут быть созданы только при выполнении, это может привести к ненужным издержкам и по времени, и по памяти.
В Ada 95 добавлены специальные средства создания алиасов, названные типами обобщенного доступа (general access types), но на них наложены ограничения для предотвращения создания повисших ссылок (см.
и специальный синтаксис как для
раздел 8.3). Предусмотрен и специальный синтаксис как для объявления указателя, так и для
переменной с алиасом:
type Ptr is access all Integer; -- Ptr может указывать на алиас
|
C |
P: Ptr := I'Access; -- Создать алиас
Первая строка объявляет тип, который может указывать на целочисленную переменную с алиасом, вторая строка объявляет такую переменную, и третьястрока объявляет указатель и инициализирует его адресом переменной. Такие типы обобщенного доступа и переменные с алиасом могут быть компонентами массивов и записей, что позволяет построить связанные структуры, не обращаясь к администратору памяти во время выполнения.
* Привязка к памяти
В языке С привязка к памяти тривиальна, потому что указателю может быть присвоен произвольный адрес:
|
C |
*reg = Ox1f1f; /* Присваивание по абсолютному адресу */
Благодаря использованию указателя-константы мы уверены, что адрес в reg не будет случайно изменен.
В Ada используется понятие спецификации представления для явного установления соответствия между обычной переменной и абсолютным адресом:
|
Ada |
for Reg use at 16#4fOO#; -- Адрес (в шестнадцатеричной системе)
Reg := 16#1 f1 f#; -- Присваивание по абсолютному адресу
Преимущество метода языка Ada состоит в том, что не используются явные указатели.
8.2. Структуры данных
Указатели нужны для реализации динамических структур данных, таких как списки и деревья. Кроме элементов данных узел в структуре содержит один или несколько указателей со ссылками на другие узлы (см. рис. 8.3).
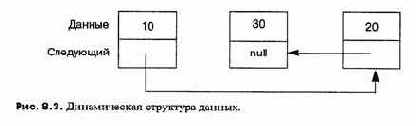
Попытка определить узел неизбежно ведет к рекурсии в определении типа, а именно: запись типа node (узел) должна содержать указатель на свойсобственный тип node.
в языках допускается задавать частичное
Для решения этой проблемы в языках допускается задавать частичное объявление записи, в котором указывается имя ее типа. Объявление сопровождается объявлением указателя, ссылающегося на это имя, а далее следует полное объявление записи, в котором уже можно ссылаться на тип указателя. В языке Ada эти три объявления выглядят так:
type Node; -- Незавершенное объявление типа
|
Ada |
type Node is -- Полное объявление
record
Data: Integer; -- Данные в узле
Next: Ptr; -- Указатель на следующий узел
end record;
Язык С требует использования тега структуры и альтернативного синтаксиса для объявления записи:
|
C |
typedef struct node { /* Объявление структуры узла*/
int data; /* Данные в узле */
Ptr next; /* Указатель на следующий узел */
} node;
В C++ нет необходимости использовать typedef, поскольку struct определяет как тег структуры, так и имя типа:
|
C++ |
struct node { /* Объявление структуры узла */
int data; /* Данные в узле */
Ptr next; /* Указатель на следующий узел */
}
Алгоритмы для прохождения (traverse) структур данных используют переменные-указатели. Следующий оператор в С — это поиск узла, поле данных которого содержит key:
|
C |
Структуры данных характеризуются числом указателей,
while (current->data != key)
current = current->next;
Аналогичный оператор в Ada (использующий неявное раскрытие ссылки) таков:
while Current.Data /= Key loop
|
Ada |
end loop;
Структуры данных характеризуются числом указателей, хранящихся в каждом узле, тем, куда они указывают, и алгоритмами, используемыми для прохождения структур и их обработки. Все алгоритмы, излагаемые в учебных курсах по структурам данных, достаточно просто программируются на языках С или Ada с использованием записей и указателей.
Указатель null (пустой)
На рисунке 8.3 поле next последнего элемента списка не указывает ни на что. Обычно считается, что такой указатель имеет специальное значение — пустое, которое отличается от любого допустимого указателя. Пустое значение в Ada обозначается зарезервированным словом null. В предыдущем разделе, чтобы не пропустить конец списка, поиск фактически следовало бы запрограммировать следующим образом:
|
Ada |
Current := Current.Next;
end loop;
Обратите внимание, что укороченное вычисление (см. раздел 6.2) здесь существенно.
В языке С используется обычный целочисленный литерал «ноль» для обозначения пустого указателя:
|
C |
current = current->next;
Нулевой литерал — это всего лишь синтаксическое соглашение; реальное значение зависит от компьютера. При просмотре с помощью отладчика в пустом указателе все биты могут быть, а могут и не быть нулевыми. Для улучшения читаемости программы в библиотеке С определен символ NULL:
|
C |
current = current->next;
Когда объявляется переменная, например целая, ее значение не определено. И это не вызывает особых проблем, поскольку любая комбинация битов задает допустимое целое число.
Однако указатели, которые не являются
Однако указатели, которые не являются пустыми и при этом не ссылаются на допустимые блоки памяти, могут вызвать серьезные ошибки. Поэтому в Ada каждая переменная-указатель неявно инициализируется как null. В языке С каждая глобальная переменная неявно инициализируется как ноль; глобальные переменные-указатели инициализируются как пустые. Позаботиться о явной инициализации локальных указателей должны вы сами.
Нужно быть очень осторожными, чтобы случайно не разыменовать пустой указатель, потому что значение null не указывает ни на что (или, вернее, ссылается на данные системы по нулевому адресу):
|
Ada |
Current := Current.Next;
В языке Ada эта ошибка будет причиной исключительной ситуации (см. гл. 11), но в С результат попытки разыменовывать null может привести к катастрофе. Операционные системы, которые защищают программы друг от друга, смогут прервать «провинившуюся» программу; без такой защиты разыменование могло бы вмешаться в другую программу или даже разрушить систему.
Указатели на подпрограммы
В языке С указатель может ссылаться на функцию. При программировании это чрезвычайно полезно в двух случаях:
• при передаче функции как параметра,
• при создании структуры данных, которая каждому ключу или индексу ставит в соответствие процедуру.
Например, один из параметров пакета численного интегрирования — это функция, которую нужно проинтегрировать. Это легко запрограммировать в С, создавая тип данных, который является указателем на функцию; функция получит параметр типа float и вернет значение типа float:
|
C |
Этот синтаксис довольно плох потому, что имя типа (в данном случае — Func) находится глубоко внутри объявления, и потому, что старшинство операций в С требует дополнительных круглых скобок.
Раз тип объявлен, он может использоваться как тип формального параметра:
Func f, float upper, float
|
C |
{
float u = f (upper); float I = f(lower);
}
Обратите внимание, что раскрытие указателя делается автоматически, когда вызывается функция-параметр, иначе нам пришлось бы написать (*f )(upper). Теперь, если определена функция с соответствующей сигнатурой, ее можно использовать как фактический параметр для подпрограммы интегрирования:
|
C |
{
… /* Определение "fun" */
}
float x = integrate(fun, 1.0, 2.0); /* "fun" как фактический параметр */
Структуры данных с указателями на функции используются при создании интерпретаторов — программ, которые получают последовательность кодов и выполняют действия в соответствии с этими кодами. В то время как статический интерпретатор может быть реализован с помощью case-оператора и обычных вызовов процедур, в динамическом интерпретаторе соответствие между кодами и операциями будет устанавливаться только во время выполнения. Современные системы с окнами используют аналогичную методику программирования: программист должен предоставить возможность обратного вызова (callback), т.е. процедуру, обеспечивающую выполнение соответствующего действия для каждого события. Это указатель на подпрограмму, которая будет выполнена, когда получен код, указывающий, что событие произошло:
typedef enum {Event1, ..., Event'10} Events;
|
C |
/* Указатель на процедуру */
Actions action [10];
/* Массив указателей на процедуры */
Во время выполнения вызывается процедура, которая устанавливает соответствие между событием и действием:
void insta!l(Events e, Actions a)
|
C |
action[e] = a;
}
когда событие происходит, его код
Затем, когда событие происходит, его код может использоваться для индексации и вызова соответствующей подпрограммы:
|
C |
Поскольку в Ada 83 нет указателей на подпрограммы, эту технологию нельзя запрограммировать без использования нестандартных средств. Когда язык разрабатывался, указатели на подпрограммы были опущены, потому что предполагалось, что родовых (generics)* программных модулей (см. раздел 10.3) будет достаточно для создания математических библиотек, а методика обратного вызова еще не была популярна. В Ada 95 этот недостаток устранен, и разрешены указатели на подпрограммы. Объявление математической библиотечной функции таково:
|
Ada |
-- Тип: указатель на функцию
function lntegrate(F: Func; Upper, Lower: Float);
-- Параметр является указателем на функцию
а обратный вызов объявляется следующим образом:
|
Ada |
type Actions is access procedure;
-- Тип: указатель на процедуру
Action: array(Events) of Actions;
-- Массив указателей на процедуры
Указатели и массивы
В языке Ada в рамках строгого контроля типов единственно допустимые операции на указателях — это присваивание, равенство и разыменование. В языке С, однако, считается, что указатели будут неявными последовательными адресами, и допустимы арифметические операции над значениями указателей. Это ясно из взаимоотношений указателей и массивов: указатели рассматриваются как более простое понятие, а доступ к массиву определяется в терминах указателей. В следующем примере
int *ptr; /* Указатель на целое */
|
C |
ptr = &а[0]; /* Явный адрес первого элемента
два оператора присваивания эквивалентны, потому
*/ ptr = а; /* Неявный тот же адрес */
два оператора присваивания эквивалентны, потому что имя массива рассматривается всего лишь как указатель на первый элемент массива. Более того, если прибавление или вычитание единицы делается для указателя, результат будет не числом, а результатом увеличения или уменьшения указателя на размер типа, на который ссылается указатель. Если для целого числа требуются четыре байта, а р содержит адрес 344, то р+1 равно не 345, а 348, т.е. адресу «следующего» целого числа. Доступ к элементу массива осуществляется прибавлением индекса к указателю и разыменованием, следовательно, два следующих выражения эквивалентны:
|
C |
a[i]
Несмотря на эту эквивалентность, в языке С все же остается значительное
различие между массивом и указателем:
|
C |
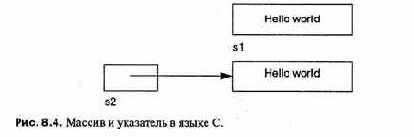
char *s2 = "Hello world";
Здесь s1 — это место расположения последовательности из 12 байтов, содержащей строку, в то время как s2 — это переменная-указатель, содержащая адрес аналогичной последовательности байтов (см. рис. 8.4). Однако s1[i] —это то же самое, что и *(s2+i) для любого i из рассматриваемого диапазона, потому что массив при использовании автоматически преобразуется в указатель.
Проблема арифметических операций над указателями состоит в том, что нет никакой гарантии, что результат выражения действительно ссылается на элемент массива. Тогда как нотацию индексации относительно легко понять и быть уверенным в ее правильности, арифметических операций над указателями по возможности следует избегать. Однако они могут быть очень полезны для улучшения эффективности в циклах, если ваш оптимизатор недостаточно хорош.
8.3. Распределение памяти
При выполнении программы память используется для хранения как программ (кода), так и различных структур данных, например стека.
и освобождение памяти правильнее обсуждать
Хотя распределение и освобождение памяти правильнее обсуждать в контексте компиляторов и операционных систем, вполне уместно сделать обзор этой темы здесь, потому что реализация может существенно повлиять на выбор конструкций языка и стиля программирования.
Существует пять типов памяти, которые должны быть выделены.
Код. Машинные команды, которые являются результатом компиляции программы.
Константы. Небольшие константы, такие как 2 и 'х', часто могут содержаться внутри команды, но для больших констант память должна выделяться особо, в частности для констант с плавающей точкой и строк.
Стек. Стековая память используется в основном для записей активации, которые содержат параметры, переменные и ссылки. Она также используется для временных переменных при вычислении выражений.
Статические данные. Это переменные, объявленные в главной программе и в других местах: в Ada — данные, объявленные непосредственно внутри библиотечных пакетов; в С — данные, объявленные непосредственно внутри файла или объявленные как статические (static) в блоке.
Динамическая область. Динамическая область (куча — heap) — термин, используемый для области данных, из которой данные динамически выделяются командой malloc в С и new в Ada и C++.
Код и константы похожи тем, что они определяются во время компиляции и уже не изменяются. Поэтому в дальнейшем обсуждении мы объединим эти два типа памяти вместе. Обратите внимание, что, если система это поддерживает, код и константы могут храниться в памяти, доступной только для чтения (ROM). Стек обсуждался подробно в разделе 7.6.
Мы упомянули, что статические (глобальные) данные можно считать распределенными в начале стека. Однако статические данные обычно распределяются независимо. Например, в Intel 8086 каждая область данных (называемая сегментом) ограничена 64 Кбайтами. Поэтому есть смысл выделять отдельный сегмент для стека помимо одного или нескольких сегментов для статических данных.
И наконец, мы должны выделить
И наконец, мы должны выделить память для кучи. Динамическая область отличается от стека тем, что выделение и освобождение памяти может быть очень хаотичным. Исполняющая система должна применять сложные алгоритмы, чтобы гарантировать оптимальное использование динамической области.
Программа обычно помещается в отдельную, непрерывную область. Память должна быть разделена так, чтобы разместить требуемые области памяти. На рисунке 8.5 показано, как это реализуется. Поскольку области кода, констант и статических данных имеют фиксированные размеры, они распределяются в начале памяти. Две области переменной длины, куча и стек помещаются в противоположные концы остающейся памяти.

При таком способе, если программа использует большой стек во время одной фазы вычисления и большую кучу во время другой фазы, то меньше шансов, что памяти окажется недостаточно.
Важно понять, что каждое выделение памяти в стеке или в куче (то есть каждый вызов процедуры и каждое выполнение программы выделения памяти) может закончиться неудачей из-за недостатка памяти. Тщательно разработанная программа должна уметь восстанавливаться при недостатке памяти, но такую ситуацию нелегко обработать, потому что процедуре, которая выполняет восстановление, может понадобиться еще больший объем памяти! Поэтому желательно получать сигнал о недостатке памяти, когда еще остается значительный резерв.
Запрос и освобождение памяти
В процедурных языках программирования есть явные выражения или операторы запроса и освобождения памяти. Язык С использует malloc, функцию весьма опасную, поскольку в ней никак не проверяется соответствие выделенного объема памяти размеру указуемого объекта. Следует использовать функцию sizeof, даже когда это явно не требуется:
|
C |
int *p = (int *) malloc(sizeof(int)); /* Этот вариант лучше */
Обратите внимание, что malloc возвращает
Обратите внимание, что malloc возвращает нетипизированный указатель, который должен быть явно преобразован к требуемому типу.
При освобождении памяти задавать размер блока не нужно:
free(p);
Выделенный блок памяти включает несколько дополнительных слов, которые используются для хранения размера блока." Этот размер используется в алгоритмах управления динамической областью, как описано ниже.
Языки C++ и Ada используют нотацию, из которой ясно видно, что создается указуемый объект конкретного типа. При этом нет опасности несовместимости типа и размера объекта:
typedef Node *Node_Ptr;
Node_Ptr *p = new Node; // C++
type Node_Ptr is access Node;
P: Node_Ptr := new Node; --Ada
Оператор delete освобождает память в C++. Ada предпочитает, чтобы вы не освобождали память, выделенную в куче, потому что освобождение памяти опасно по существу (см. ниже). Конечно, на практике без освобождения не обойтись, поэтому применяемый метод назван освобождением без контроля (unchecked deallocation), и назван он так для напоминания, что его использование опасно. Обратите внимание, что освобождаемая память — это область хранения указуемого объекта (на который ссылается указатель), а не самого указателя.
Повисшие ссылки
Серьезная опасность, связанная с указателями, — это возможность создания повисших ссылок (danglingpointers) при освобождении блока памяти:
|
C++ |
ptr2 = ptrl; // Оба указывают на один и тот же блок
result = delete ptrl; // ptr2 теперь указывает на освобожденный блок
После выполнения первого присваивания оба указателя ссылаются на выделенный блок памяти. Когда память освобождена, второй указатель все еще сохраняет копию адреса, но этот адрес теперь не имеет смысла.
В алгоритме со сложной структурой
В алгоритме со сложной структурой данных нетрудно создать двойную ссылку такого рода по ошибке.
Повисшие ссылки могут возникать также в С и C++ без какого-либо явного участия программиста в освобождении памяти:
|
C |
{
char с; /* Локальная переменная */
return &c; /* Указатель на локальную переменную типа
char */
}
Память для с неявно выделяется в стеке при вызыве процедуры и неявно освобождается после возврата из процедуры, поэтому возвращенное значение указателя больше не ссылается на допустимый объект. Это легко увидеть в процедуре из двух строк, но, возможно, не так легко заметить в большой программе.
Ada пытается избежать повисших ссылок.
• Указатели на объекты (именованные переменные, константы и параметры) запрещены в Ada 83; в Ada 95 они вводятся специальной конструкцией alias, правила которой предотвращают возникновение повисших ссылок.
• Явного выделения памяти избежать нельзя, поэтому применяемый метод назван Unchecked Deallocation (освобождение без контроля) с целью предупредить программиста об опасности.
8.4. Алгоритмы распределения динамической памяти
Менеджер кучи — это компонент исполняющей системы, который выделяет и освобождает память. Это делается посредством поддержки списка свободных блоков. Когда сделан запрос на выделение памяти, она ищется в этом списке, а при освобождении блок снова подсоединяется к списку свободных блоков. Разработчик исполняющей системы должен рассмотреть много вариантов и принять проектные решения, в частности по порядку обработки блоков, их структуре, порядку поиска и т. д.
.
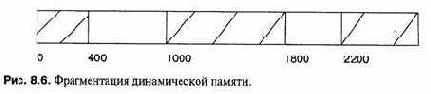
С распределением динамической области памяти связана проблема фрагментации.
показана ситуация, когда сначала
На рисунке 8. 6 показана ситуация, когда сначала были выделены пять блоков памяти, а затем второй и четвертый освобождены. Теперь, хотя доступны 1000 байтов, невозможно выделить больше 600 байтов, потому что память раздроблена на небольшие блоки. Даже когда третий блок освободится, памяти будет достаточно только при условии, что менеджер кучи «умеет» сливать смежные свободные блоки.
В добавление к слияниям менеджер кучи может предупреждать фрагментацию, отыскивая блок подходящего размера, а не просто первый доступный, или выделяя большие блоки из одной области динамической памяти, а небольшие блоки — из другой. Существует очевидный компромисс между сложностью менеджера и издержками времени выполнения.
Программист должен знать используемые алгоритмы управления динамической памятью и писать программу с учетом этих знаний.
Другая возможность ослабить зависимость от алгоритмов работы менеджера кучи — это завести кэш освобождаемых блоков. Когда блок освобождается, он просто подсоединяется к кэшу. Когда необходимо выделить блок, сначала проверяется кэш; это позволяет избежать издержек и фрагментации, возникающих при обращениях к менеджеру кучи.
В Ada есть средство, которое позволяет программисту задать несколько куч разного размера, по одной для каждого типа указателя. Это позволяет предотвратить фрагментацию, но повышает вероятность того, что в одной куче память будет исчерпана, в то время как в других останется много свободных блоков.
Виртуальная память
Есть один случай, когда распределение динамической памяти совершенно надежно — это когда используется виртуальная память. В системе с виртуальной памятью программисту предоставляется настолько большое адресное пространство, что переполнение памяти фактически невозможно. Операционная система берет на себя распределение логического адресного пространства в физической памяти, когда в этом возникает необходимость.
зическая память исчерпана, блоки памяти,
Когда фи зическая память исчерпана, блоки памяти, называемые страницами, выталкиваются на диск.
С помощью виртуальной памяти менеджер кучи может продолжать выделение динамической памяти почти бесконечно, не сталкиваясь с проблемой фрагментации. Единственный риск — это связанная с виртуальной памятью ситуация пробуксовки (thrashing), которая происходит, когда код и данные, требуемые для фазы вычисления, занимают так много страниц, что в памяти для них не хватает места. На подкачку страниц тратится так много времени, что вычисление почти не продвигается.
Сборка мусора
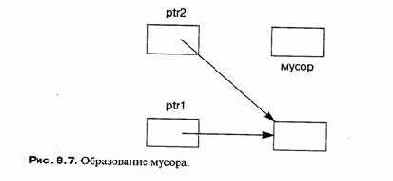
Последняя проблема, связанная с динамической памятью, — образование мусора (garbage), например:
int *ptr1 = new int; // Выделить первый блок
|
C |
ptr2 = ptrl; // Второй блок теперь недоступен
После оператора присваивания второй блок памяти доступен через любой из указателей, но нет никакого способа обратиться к первому блоку (см. рис. 8.7). Это может и не быть ошибкой, потому что память, к которой нельзя обратиться, (называемая мусором) не может вам помешать. Однако, если продолжается утечка памяти, т. е. образуется мусор, в конечном счете программа выйдет из строя из-за недостатка памяти. Чрезвычайно трудно локализовать причину утечки памяти, потому что нет прямой связи между причиной и симптомом (недостатком памяти).
Очевидное решение состоит в том, чтобы не создавать мусор, прежде всего тщательно заботясь об освобождении каждого блока до того, как он станет недоступен. Кроме того, исполняющая система языка программирования может содержать сборщик мусора (garbage collector). Задача сборщика мусора состоит в том, чтобы «повторно использовать» мусор, идентифицируя недоступные блоки памяти и возвращая их менеджеру динамической памяти. Существует два основных алгоритма сборки мусора: один из них для каждого блока
ведет счетчик текущего числа указателей,
ведет счетчик текущего числа указателей, ссылающихся на этот блок, и автоматически освобождает блок, когда счетчик доходит до нуля. Другой алгоритм отмечает все доступные блоки и затем собирает немаркированные (и, следовательно, недоступные) блоки. Первый алгоритм проблематичен, потому что группа блоков, каждый из которых является мусором, могут указывать друг на друга так, что счетчик никогда не сможет уменьшиться до нуля. Второй алгоритм требует прерывания вычислений на длительные периоды времени, чтобы маркировку и сбор можно было выполнить без влияния вычислений. Это, конечно, недопустимо в интерактивных системах.
Сборка мусора традиционно выполняется в таких языках, как Lisp и Icon, которые создают большое число временных структур данных, быстро становящихся мусором. Проведены обширные исследования по сборке мусора; особое внимание в них уделено параллельным и пошаговым методам, которые не будут нарушать интерактивные вычисления или вычисления в реальном масштабе времени. Eiffel — один из немногих процедурных языков, которые включают сборщики мусора в свои исполняющие системы.
8.5. Упражнения
1. Как представлен на вашем компьютере указатель? Как представлен на вашем компьютере указатель null?
2. Напишите на языке С алгоритм обработки массива с помощью индексации, а затем измените его, чтобы использовать явные операции с указателями. Сравните получающиеся в результате машинные команды и время выполнения двух программ. Есть ли различие в оптимизации?
3. Покажите, как можно применить «часовых», чтобы сделать поиск в списке более эффективным.
4. Почему не была использована операция адресации для фактического параметра, являющегося указателем на функцию:
|
C |
5. Покажите, как можно использовать повисшие ссылки, чтобы разрушить систему типов.
в Ada 95 определение доступности
6. Изучите в Ada 95 определение доступности (accessibility) и покажите, как правила предотвращают возникновение повисших ссылок.
7. Напишите программу обработки динамической структуры данных, например связанного списка. Измените программу, чтобы использовать кэш узлов.
8. Изучите документацию вашего компилятора; с помощью каких алгоритмов исполняющая система распределяет динамическую память? Есть ли какие-либо издержки по памяти при выделении динамической памяти, т. е. выделяются ли лишние слова кроме тех, которые вы запросили? Если да, то сколько?
9. Если у вас есть доступ к компьютеру, который использует виртуальную память, посмотрите, как долго можно продолжать запрашивать память. При нарушении каких пределов выделение памяти прекращается?
Глава 9
Вещественные числа
9.1. Представление вещественных чисел
В главе 4 мы обсуждали, как целочисленные типы используются для представления подмножества математических целых чисел. Вычисления с целочисленными типами могут быть причиной переполнения — это понятие не име-ет никакого смысла для математических целых чисел — а возможность пере-полнения означает, что коммутативность и ассоциативность арифметических
операций при машинных вычислениях не гарантируются.
Представление вещественных чисел в компьютерах и вычисления с этими представлениями чрезвычайно проблематичны — до такой степени, что при создании важных программ полезно консультироваться со специалистами. В этой главе будут изучены основные понятия, связанные с использованием ве- щественных чисел в вычислениях; чрезвычайная легкость написания в про-грамме вычислений с вещественными числами не должна заслонять глубин-ные проблемы.
Прежде всего обратим внимание на то, что десятичные числа не всегда можно точно представить в двоичной нотации.
Представлять непосредственно десятичные числа, например,
Например, нельзя точно пред-ставить в виде двоичного числа 0.2 (одну пятую), а только как периодическую I двоичную дробь:
0.0011001100110011..
Существуют два решения этой проблемы:
• Представлять непосредственно десятичные числа, например, каждому десятичному символу ставить в соответствие четыре бита. Такое представление называется двоично-кодированным десятичным числом (BCD — binary-coded decimal).
• Хранить двоичные числа и принять как факт то, что некоторая потеря точности иногда может случаться.
Представление BCD приводит к некоторому перерасходу памяти, потому что с помощью четырех битов можно представить 16 разных значений, а не 10, необходимых для представления десятичных чисел. Более существенный не-достаток состоит в том, что это представление не «естественно», и вычисление с BCD выполняется намного медленнее, чем с двоичными числами. Таким образом, мы ограничимся обсуждением двоичных представлений; читателя, интересующегося вычислениями с BCD, можно отослать к таким языкам, как Cobol, которые поддерживают числа BCD.
Числа с фиксированной точкой
Для простоты последующее обсуждение будет вестись в терминах десятичных чисел, но оно справедливо и для двоичных. Предположим, что мы можем представить в 32-разрядном слове памяти семь цифр: пять до и две после десятичной точки:
12345.67, -1234.56, 0.12
Такое представление называется представлением с фиксированной точкой. Преимущество чисел с фиксированной точкой состоит в том, что количество знаков после запятой, которое определяет абсолютную ошибку, фиксировано. Если перечисленные выше числа обозначают доллары и центы, то любая ошибка, вызванная ограниченным размером слова памяти, не превышает одного цента. Недостаток же состоит в том, что точность представления, то есть относительная ошибка, которая определяется числом значащих цифр, является переменной.
Первое число использует все семь
Первое число использует все семь цифр представления, имеющихся в распоряжении, тогда как последнее число использует только две цифры. Хуже то, что переменная точность представления означает, что многие важные числа, такие как сумма $1532 854.07, которую вы выиграли в лотерее, или размер $0.00572 вашего подоходного налога, вообще никак нельзя представить.
Числа с фиксированной точкой используются в приложениях, где существенна абсолютная ошибка в конечном результате. Например, бюджетные вычисления обычно делаются с фиксированной точкой, так как требуемая точность представления известна заранее (скажем, 12 или 16 цифр), а бюджет должен быть сбалансирован до последнего цента. Числа с фиксированной точкой также используются в системах управления, где для взаимодействия датчиков и силовых приводов с компьютером используются слова или поля фиксированной длины. Например, скорость можно представить 10-битовым полем с диапазоном значений от 0 до 102.3 км/час; один бит будет представлять 0.1 км/час.
Числа с плавающей точкой
Ученые, которым приходится иметь дело с широким диапазоном чисел, часто используют так называемую научную нотацию
123.45 х 103, 1.2345 х 108, -0.00012345 х 107 12345000.0 х 104
Как можно использовать эту нотацию на компьютере? Сначала обратите внимание на то, что здесь присутствуют три элемента информации, которые должны быть представлены: знак, мантисса (123.45 в первом числе) и экспонента.
На первый взгляд кажется, что нет никакого преимущества в представлении чисел в научной нотации, потому что для представления мантиссы нужна разная точность: пять цифр в первом и втором числах и по восемь цифр для двух других чисел.
Однако, как можно заметить, конечные нулевые цифры мантиссы, большей 1.0 (и ведущие нулевые цифры мантиссы, меньшей 1.0), можно отбросить, если изменить значение (не точность!) экспоненты. Другими словами, мантиссу можно неоднократно умножать или делить на 10 до тех пор, пока она находится в форме, которая использует максимальную точность представления; при каждой такой операции экспонента будет уменьшаться или увеличиваться на 1 соответственно.
с помощью мантиссы из пяти
Например, последние два числа можно записать с помощью мантиссы из пяти цифр:
-0.12345 х104 0.12345 х1012
Для вычислений на компьютере удобно, когда числа представляются в такой
стандартной форме, называемой нормализованной, в которой первая ненулевая цифра является разрядом десятых долей числа. Это также позволяет сэкономить место в представлении, поскольку десятичная точка всегда находится в одной и той же позиции, и ее не нужно представлять явно. Представление называется с плавающей точкой, потому что десятичная точка «плавает» влево или вправо до тех пор, пока число не будет представлено с максимальной точностью.
В чем основной недостаток вычислений, использующих числа с плавающей точкой? Рассмотрим число 0.12345 х 10'°, которое является нормализованной формой с плавающей точкой для числа
1 234 500 000
и предположим, что таким образом банк представил ваш депозит в размере
$1 234 567 890
Управляющий банком был бы горд тем, что относительная ошибка:
67 890
1 234 567 890
является очень малой долей процента, но вы оправданно потребовали бы ваши $67 890, которые составляют абсолютную ошибку.
Однако в научных вычислениях относительная ошибка намного важнее абсолютной погрешности. В программе, которая контролирует скорость ра-кеты, требование может состоять в том, чтобы ошибка не превышала 0,5%, Хотя это составляет несколько километров в час во время запуска, и несколь-ко сотен километров в час при приближении к орбите. Вычисления с плавающей точкой используются гораздо чаще, чем с фиксированной точкой, пото-му что относительная точность требуется намного чаще, чем абсолютная. По Этой причине в большинстве компьютеров есть аппаратные средства, которые Непосредственно реализуют вычисления с плавающей точкой.
с плавающей точкой хранятся как
Представление чисел с плавающей точкой
Числа с плавающей точкой хранятся как двоичные числа в нормализованной форме, которую мы описали:
-0.101100111 х215
При типичной реализации на 32-разрядном компьютере 1 бит выделяется для знака, 23 бита — для мантиссы и 8 битов — для экспоненты. Поскольку для хранения одной десятичной цифры требуется Iog2 10 = 3.3 бита, то точность представления составит 23/3.3 = 7 цифр. Если необходима большая точность, то с помощью 64-разрядного двойного слова с 52-разрядной мантиссой можно получить приблизительно 15 цифр точности представления.
Существует «трюк», с помощью которого можно увеличить количество представимых чисел. Так как все числа с плавающей точкой нормализованы и первая цифра нормализованной мантиссы обязательно 1, эту первую цифру можно не представлять явно.
Экспонента со знаком представляется со смещением так, чтобы представление было всегда положительным, и помещается в старшие разряды слова после знакового бита. Это позволяет упростить сравнения, потому что можно воспользоваться обычными целочисленными сравнениямии не выделять специально поля экспоненты со знаком. Например, 8-разрядное поле экспоненты со значениями в диапазоне 0 .. 255 представляет экспоненты в диапазоне -127 .. 128 со смещением 127.
Мы можем теперь расшифровать битовую строку как число с плавающей точкой. Строка
1 1000 1000 0110 0000 0000 0000 0000 000
расшифровывается следующим образом.
• Знаковый бит равен 1, поэтому число отрицательное.
• Представление экспоненты равно 1000 1000 = 128 + 8 = 136. Удаление смещения дает
136-127 = 9
• Мантисса равна 0.10110 ... (обратите внимание, что восстановлен скрытый бит), т. е.
1/2+1/8+.1/16 = 11/16
• Таким образом, хранимое число равно 29 х 11/16 = 352.
Как и для целых чисел, для чисел с плавающей точкой переполнение (overflow) происходит, когда результат вычисления слишком большой:
Так как самая большая экспонента,
(0.5x2™) • (0.5 х 280) = 0.25 х 2150
Так как самая большая экспонента, которая может быть представлена, равна 128, происходит переполнение. Рассмотрим теперь вычисление:
(0.5 х2-70) • (0.5 х 2-80) = 0.25 х 2-150
Говорят, что при вычислении происходит потеря значимости (underflow), когда результат слишком мал, чтобы его можно было представить. Вы можете воскликнуть, что такое число настолько мало, что его можно принять равным нулю, и компьютер может интерпретировать потерю значимости именно так, но на самом деле потеря значимости часто говорит об ошибке, которая требует обработки или объяснения.
9.2. Языковая поддержка вещественных чисел
Все языки программирования имеют поддержку вычислений с плавающей точкой. Переменная может быть объявлена с типом float, а литералы с плавающей точкой представлены в форме, близкой к научной нотации:
|
C |
float f2 = -46.64E-3;
Обратите внимание, что литералы не нужно представлять в двоичной записи или в нормализованной форме; это преобразование делается компилятором.
Для осмысленных вычислений с плавающей точкой необходимо минимум 32 разряда. Однако часто такой точности недостаточно, поэтому языки поддерживают объявления и вычисления с более высокой точностью. Как минимум, поддерживаются переменные с двойной точностью (double-precision), использующие 64 разряда, а некоторые компьютеры или компиляторы поддерживают даже более длинные типы. Двойная точность типов с плавающей точкой называется double в языке С и Long_Float в Ada.
Запись литералов с двойной точностью может быть разной в различных языках. Fortran использует специальную запись, заменяя Е, предшествующее экспоненте, на D: -45.64D - 3. В языке С каждый литерал хранится с двойной точностью, если же вы хотите задать одинарную точность, то используется суффикс F. Обратите на это внимание, если вы храните большой массив констант с плавающей точкой.
работки переменной точности представления литералов.
Ada вводит новое понятие — универсальные типы (universal types) — для об работки переменной точности представления литералов. Такой литерал как 0.2 хранится компилятором с потенциально неограниченной точностью (вспомните, что 0.2 нельзя точно представить как двоичное число). Фактически при использовании литерала он преобразуется в константу с той точностью, которая нужна:
|
Ada |
PI_L: constant Long_Float :=3.1415926535;
PI: constant := 3.1415926535;
F: Float := PI; -- Преобразовать число к типу Float
L: Long_Float := PI; -- Преобразовать число к типу Long_Float
В первых двух строках объявляются константы именованных типов. Третье объявление для PI называется именованным числом (named number) и имеет универсальный вещественный тип. Фактически, в инициализациях PI преобразуется к нужной точности.
Четыре арифметические операции (+,-,* и /), так же как и операции отношения, определены для типов с плавающей точкой. Такие математические функции, как тригонометрические, могут быть определены в рамках языка (Fortran и Pascal) или поставляться с библиотеками подпрограмм (С и Ada).
Плавающая точка и переносимость
При переносе программ, использующих плавающую точку, могут возникнуть трудности из-за различий в определении спецификаторов типа. Ничто не мешает компилятору для С или Ada использовать 64 разряда для представления float (Float) и 128 разрядов для представления double (Long_Float). Перенос на другую машину проблематичен в обоих направлениях. При переносе с машины, где реализовано представление float с высокой точностью на машину, использующую представление с низкой точностью, все типы float должны быть преобразованы в double, чтобы сохранить тот же самый уровень точности.
с низкой точностью на машину
При переносе с машины с низкой точностью на машину с высокой точностью может потребоваться противоположное изменение, потому что выполнение с избыточной точностью приводит к потерям времени и памяти.
Простейшее частное решение состоит в том, чтобы объявлять и использовать искусственный тип с плавающей точкой; в этом случае при переносе программы нужно будет изменить только несколько строк:
typedef double Real; /* С */
subtype Real is Long_Float; -- Ada
Решение проблемы переносимых вычислений с вещественными числами в Ada
см. в разделе 9.4.
Аппаратная и программная плавающая точка
Наше обсуждение представления чисел с плавающей точкой должно было прояснить, что арифметика на этих значениях является сложной задачей. Нужно разбить слова на составные части, удалить смещение экспоненты, выполнить арифметические операции с несколькими словами, нормализовать результат и представить его как составное слово. Большинство компьютеров использует специальные аппаратные средства для эффективного выполнения вычислений с плавающей точкой.
Компьютер без соответствующих аппаратных средств может все же выполнять вычисления с плавающей точкой, используя библиотеку подпрограмм, которые эмулируют (emulate) команды с плавающей точкой. Попытка выполнить команду с плавающей точкой вызовет прерывание «несуществующая команда», которое будет обработано с помощью вызова соответствующей подпрограммы эмуляции. Само собой разумеется, что это может быть очень неэффективно, поскольку существуют издержки на прерывание и вызов подпрограммы, не говоря о самом вычислении с плавающей точкой.
Если вы предполагаете, что ваша программа будет активно использоваться на компьютерах без аппаратной поддержки плавающей точки, может быть разумнее совсем ей не пользоваться и явно запрограммировать вычисления с фиксированной точкой.
финансовая программа может делать все
Например, финансовая программа может делать все вычисления в центах вместо долей доллара. Конечно, при этом возникает риск переполнения, если типы Integer или Long_integer не представлены с до- статочной точностью.
Смешанная арифметика
В математике очень часто используются смешанные арифметические операции с целыми и вещественными числами: мы пишем А = 2pi*r, а не А = 2.0pi*r. При вычислении смешанные операции с целыми числами и числами с плавающей точкой должны выполняться с некоторой осторожностью. Предпочтительнее вторая форма, потому что 2.0 можно хранить непосредственно как константу с плавающей точкой, а литерал 2 нужно было бы преобразовать к представлению с плавающей точкой. Хотя обычно это делается компилятором автоматически, лучше точно написать, что именно вам нужно.
Другой потенциальный источник затруднений — различие между целочисленным делением и делением с плавающей точкой:
|
Ada |
J: Integer := I / 2;
К: Integer := lnteger(Float(l) / 2.0);
Bыражение в присваивании J задает целочисленное деление; результат, ко-нечно, равен 3. В присваивании К требуется деление с плавающей точкой: ре-зультат равен 3.5, и он преобразуется в целое число путем округления до 4.
В языках даже нет соглашений относительно того, как преобразовывать значения с плавающей точкой в целочисленные. Тот же самый пример на языке С выглядит так:
int i = 7;
|
C |
int k = (int) ((float i)/ 2.0);
Здесь 3 присваивается как j, так и k, потому что значение 3.5 с плавающей точкой обрезается, а не округляется!
В языке С неявно выполняется смешанная арифметика, в случае необходимости целочисленные типы преобразуются к типам с плавающей точкой, а более низкая точность к более высокой. Кроме того, значения неявно преобразуются при присваивании. Таким образом, вышеупомянутый пример можно было бы написать как
|
C |
к плавающему типу вполне распознаваемо,
«Продвижение» целочисленного i к плавающему типу вполне распознаваемо, и тем не менее для лучшей читаемости программ в присваиваниях (в отличие от инициализаций) преобразования типов лучше задавать явно:
|
C |
В Ada вся смешанная арифметика запрещена; однако любое значение числового типа может быть явно преобразовано в значение любого другого числового типа, как показано выше.
Если важна эффективность, реорганизуйте смешанное выражение так, чтобы вычисление оставалось по возможности простым как можно дольше. Рассмотрим пример (вспомнив, что литералы в С рассматриваются как double):
|
C |
Здесь было бы выполнено преобразование i к типу double, затем умножение 2.2 * i и так далее для каждого целого числа, преобразуемого к типу double. Наконец, результат был бы преобразован к типу float. Эффективнее было бы написать:
|
C |
float f=2.2F*(i*J*k*l);
чтобы гарантировать, что сначала будут перемножены целочисленные переменные с помощью быстрых целочисленных команд и что литерал будет храниться как float, а не как double. Конечно, такая оптимизация может привести к целочисленному переполнению, которого могло бы не быть, если вычисление выполнять с двойной точностью.
Одним из способов увеличения эффективности любого вычисления с плавающей точкой является изменение алгоритма таким образом, чтобы только часть вычислений должна была выполняться с двойной точностью. Например, физическая задача может использовать одинарную точность при вычислении движения двух объектов, которые находятся близко друг от друга (так что расстояние между ними можно точно представить относительно небольшим количеством цифр); программа затем может переключиться на двойную точность, когда объекты удалятся друг от друга.
9.3. Три смертных греха
Младший значащий разряд результата каждой операции с плавающей точкой может быть неправильным из-за ошибок округления.
ре пишут программное обеспечение для
Программисты, кото- ре пишут программное обеспечение для численных расчетов, должны хоро-шо разбираться в методах оценки и контроля этих ошибок. Вот три грубые ошибки, которые могут произойти:
исчезновение операнда,
умножение ошибки,
потеря значимости.
Операнд сложения или вычитания может исчезнуть, если он относительно мал по сравнению с другим операндом. При десятичной арифметике с пятью цифрами:
0.1234 х 103 + 0.1234 х 10-4 = 0.1234 х 103
Маловероятно, что преподаватель средней школы учил вас, что х + у = х для ненулевого у, но именно это здесь и произошло!
Умножение ошибки — это большая абсолютная ошибка, которая может появиться при использовании арифметики с плавающей точкой, даже если относительная ошибка мала. Обычно это является результатом умножения деления. Рассмотрим вычисление х • х:
0.1234 х103 • 0.1234 х 103 = 0.1522 х 105
и предположим теперь, что при вычислении х произошла ошибка на единицу младшего разряда, что соответствует абсолютной ошибке 0.1:
0.1235 х 103 • 0.1235 х 103 = 0.1525 х 105
Абсолютная ошибка теперь равна 30, что в 300 раз превышает ошибку перед умножением.
Наиболее грубая ошибка — полная потеря значимости, вызванная вычитанием почти равных чисел:
|
C |
float f2 = 0.12346;
B математике f2 -f1 = 0.00004, что, конечно, вполне представимо как четырехразрядное число с плавающей точкой: 0.4000 х 10-4. Однако программа, вы-числяющая f2 - f 1 в четырехразрядном представлении с плавающей точкой, даст ответ:
0.1235 10°-0.1234x10° = 0.1000 х 10-3
что даже приблизительно не является приемлемым ответом.
Потеря значимости встречается намного чаще, чем можно было бы предположить, потому что проверка на равенство обычно реализуется вычитанием и последующим сравнением с нулем. Следующий условный оператор, таким образом, совершенно недопустим:
|
C |
f2=…;
if (f1 ==f2)...
Самая невинная перестройка выражений для
Самая невинная перестройка выражений для f 1 и f2, независимо от того, сделана она программистом или оптимизатором, может вызвать переход в условном операторе по другой ветке. Правильный способ проверки равенства с плавающей точкой состоит в том, чтобы ввести малую величину:
|
C |
if ((fabs(f2-f1))<Epsilon)...
и затем сравнить абсолютное значение разности с малой величиной. По той же самой причине нет существенного различия между < = и < при вычислениях с плавающей точкой.
Ошибки в вычислениях с плавающей точкой часто можно уменьшить изменением порядка действий. Поскольку сложение производится слева направо, четырехразрядное десятичное вычисление
1234.0 + 0.5678 + 0.5678 = 1234.0
лучше делать как:
0.5678 + 0.5678 + 1234.0 = 1235.0
чтобы не было исчезновения слагаемых.
В качестве другого примера рассмотрим арифметическое тождество:
(х+у)(х-у)=х2-у2
и используем его для улучшения точности вычисления:
X, Y: Float_4;
Z: Float_7;
|
Ada |
Z := Float_7(X*X - Y*Y); -- или так?
Если мы положим х = 1234.0 и у = 0.6, правильное значение этого выражения будет равно 1522755.64. Результаты, вычисленные с точностью до восьми цифр, таковы:
(1234.0 + 0.6) • (1234.0-0.6) =1235.0 • 1233.0=1522755.0
и
(1234.0 • 1234.0)-(0.6 • 0.6) = 1522756.0-0.36 =1522756.0
При вычислении (х + у) (х- у) небольшая ошибка, являющаяся результатом сложения и вычитания, значительно возрастает при умножении. При вычислении по формуле х2 - у2 уменьшается ошибка от исчезновения слагаемого и результат получается более точным.
9.4. Вещественные типы в языке Ada
Замечание: техническое определение вещественных типов было значительно упрощено при переходе от Ada 83 к Ada 95, поэтому, если вы предполагаете детально изучать эту тему, лучше опускать более старые определения.
мы описали, как можно
Типы с плавающей точкой в Ada
В разделе 4. 6 мы описали, как можно объявить целочисленный тип, чтобы получить данный диапазон, в то время как реализация выбирается компилятором:
type Altitude is range 0 .. 60000;
Аналогичная поддержка переносимости вычислений с плавающей точкой обеспечивается объявлением произвольных типов с плавающей точкой:
type F is digits 12;
Это объявление запрашивает точность представления из 12 (десятичных) цифр. На 32-разрядном компьютере для этого потребуется двойная точность, тогда как на 64-разрядном компьютере достаточно одинарной точности. Об- ратите внимание, что, как и в случае целочисленных типов, это объявление создает новый тип, который нельзя использовать в операциях с другими типа-ми без явных преобразований.
Стандарт Ada подробно описывает соответствующие реализации такого Объявления. Программы, правильность которых зависит только от требо-ваний стандарта, а не от каких-либо причуд частной реализации, гаран-тированно легко переносимы с одного компилятора Ada на другой, даже на [компилятор для совершенно другой архитектуры вычислительной сис-темы.
Типы с фиксированной точкой в Ada
Тип с фиксированной точкой объявляется следующим образом:
type F is delta 0.1 range 0.0 .. 1.0;
Кроме диапазона при записи объявления типа с фиксированной точкой ука-зывается требуемая абсолютная погрешность в виде дроби после ключевого слова delta.
Заданные delta D и range R означают, что реализация должна предоставить набор модельных чисел, отличающихся друга от друга не больше чем на D и покрывающих диапазон R. На двоичном компьютере модельные числа были бы кратными ближайшего числа, меньшего D и являющегося степенью двойки, в нашем случае 1/16 = 0.0625. Данному выше объявлению соответствуют следующие модельные числа:
О, 1/16, 2/16,..., 14/16,15/16
Обратите внимание, что, даже если 1.0 определена как часть диапазона, это число не является одним из модельных чисел! Определение только требует, чтобы 1.0 лежала не далее 0.1 от модельного числа, и это требование выполняется, потому что 15/16 = 0.9375 и 1.0 — 0.9375 < 0.1.
Существует встроенный тип Duration, который
Существует встроенный тип Duration, который используется для измерения временных интервалов. Здесь подходит тип с фиксированной точкой, потому что время будет иметь абсолютную погрешность (скажем 0.0001 с) в зависимости от аппаратных средств компьютера.
Для обработки коммерческих данных в Ada 95 определены десятичные типы с фиксированной точкой.
type Cost is delta 0.01 digits 10;
В отличие от обычных типов с фиксированной точкой, которые представляются степенями двойки, эти числа представляются степенями десяти и, таким образом, подходят для точной десятичной арифметики. Тип, объявленный выше, может поддерживать значения до 99999999.99.
9.5. Упражнения
1. Какие типы с плавающей точкой существуют на вашем компьютере? Перечислите диапазон и точность представления для каждого типа. Используется ли смещение в представлении экспоненты? Выполняется ли нормализация? Есть ли скрытый старший бит? Существует ли представление бесконечности или других необычных значений?
2. Напишите программу, которая берет число с плавающей точкой и печатает знак, мантиссу и экспоненту (после удаления всех смещений).
3. Напишите программу для целочисленного сложения и умножения с неограниченной точностью.
4. Напишите программу для печати двоичного представления десятичной дроби.
5. Напишите программу для BCD-арифметики.
6. Напишите программу для эмуляции сложения и умножения с плавающей точкой.
7. Объявите различные типы с фиксированной точкой в Ada и проверьте, как представляются значения. Как представляется тип Duration?
8. В Ada существуют ограничения на арифметику с фиксированной точкой. Перечислите и обоснуйте каждое ограничение.
Здесь мы этим термином обозначаем
Глава 10
Полиморфизм
Полиморфизм означает «многоформенность». Здесь мы этим термином обозначаем возможность для программиста использовать переменную, значение или подпрограмму двумя или несколькими различными способами. Полиморфизм почти по определению является источником ошибок; достаточно трудно понять программу даже тогда, когда каждое имя имеет одно значение, и намного труднее, если имя может иметь множество значений! Однако во многих случаях полиморфизм необходим и достаточно надежен при аккуратном применении.
Полиморфизм может быть статическим или динамическим. В статическом полиморфизме множественные формы разрешаются (конкретизируются) на этапе компиляции, и генерируется соответствующий машинный код. Например:
• преобразование типов: значение преобразуется из одного типа в другой;
• перегрузка (overloading): одно и то же имя используется для двух или нескольких разных объектов или подпрограмм (включая операции);
• родовой (настраиваемый) сегмент: параметризованный шаблон подпрограммы используется для создания различных конкретных экземпляров подпрограммы.
В динамическом полиморфизме структурная неопределенность остается до этапа выполнения:
• вариантные и неограниченные записи: одна переменная может иметь значения разных типов;
• диспетчеризация во время выполнения: выбор подпрограммы, которую нужно вызвать, делается при выполнении.
10.1. Преобразование типов
Преобразование типов — это операция преобразования значения одного типа к значению другого типа. Существуют два варианта преобразования типов: 1) перевод значения одного типа к допустимому значению другого типа, и 2) пересылка значения как неинтерпретируемой строки битов.
Преобразование числовых значений, скажем, значений
Преобразование числовых значений, скажем, значений с плавающей точкой, к целочисленным включает выполнение команд преобразования битов значения с плавающей точкой так, чтобы они представили соответствующее целое число. Фактически, преобразование типов делается функцией, получающей параметр одного типа и возвращающей результат другого типа. Синтаксис языка Ada для преобразования типов такой же, как у функции:
|
Ada |
Float := Float(l);
в то время как синтаксис языка С может показаться странным, особенно в сложном выражении:
|
C |
float f = (float) i;
В C++ для совместимости сохранен синтаксис С, но для улучшения читаемо- сти программы также введен и функциональный синтаксис, как в Ada. Кроме того, и С, и C++ включают неявные преобразования между типами, прежде всего числовыми:
|
C |
Явные преобразования типов безопасны, потому что они являются всего
лишь функциями: если не существует встроенное преобразование типа, вы
всегда можете написать свое собственное. Неявные преобразования типов более проблематичны, потому что читатель программы никогда не знает, было
преобразование преднамеренным или это просто оплошность. Использование целочисленных значений в сложном выражении с плавающей точкой не должно вызывать никаких проблем, но другие преобразования следует указывать явно.
Вторая форма преобразования типов просто разрешает программе исполь-зовать одну и ту же строку битов двумя разными способами. К сожалению, в языке С используется один и тот же синтаксис для обеих форм преобразова-ния: если преобразование типов имеет смысл, например между числовыми типами или указательными типами, то оно выполняется; иначе строка битов передается, как есть.
В языке Ada можно между любыми двумя типами осуществить не контролируемое преобразование (unchecked conversion), при котором значение трактуется как неинтерпретируемая строка битов.
Поскольку это небезопасно по самой
Поскольку это небезопасно по самой сути и разрушает все с таким трудом добытые преимущества контроля типов, неконтролируемые преобразования не поощряются, и синтаксис языка спроектирован так, чтобы такие преобразования бросались в глаза. При просмотре программы вы не пропустите места таких преобразований и должны будете «оправдаться» хотя бы перед собой.
Хотя для совместимости в C++ сохранено такое же преобразование типов, как в С, в нем определен новый набор операций преобразования типов:
• dynamic_cast. См. раздел 15.3.
• static_cast. Выражение типа Т1 может статически приводиться к типу Т2, если Т1 может быть неявно преобразовано к Т2 или обратно; static_cast следует использовать для безопасных преобразований типов, как, например, float к int или обратно.
• reinterpret_cast. Небезопасные преобразования типов.
• const_cast. Используется, чтобы разрешить делать присваивания константным объектам.
10.2. Перегрузка
Перегрузка — это использование одного и того же имени для обозначения разных объектов в общей области действия. Использование одного и того же имени для переменных в двух разных процедурах (областях действия) не рассматривается как перегрузка, потому что две переменные не существуют одновременно. Идея перегрузки исходит из потребности использовать математические библиотеки и библиотеки ввода-вывода для переменных различных типов. В языке С имя функции вычисления абсолютного значения свое для каждого типа.
|
C |
double d=fabs( 1.57);
long I =labs(-25L);
В Ada и в C++ одно и то же имя может быть у двух или нескольких разных подпрограмм при условии, что сигнатуры параметров разные. Пока число и/или типы (а не только имена или режимы) формальных параметров различны, компилятор будет в состоянии запрограммировать вызов правильной подпрограммы, проверяя число и типы фактических параметров:
function Sin(X: in Float) return Float;
Интересное различие между двумя языками
function Sin(X: in Long_Float) return Long_Float;
|
Ada |
L1.L2: Long_Float:
F1 :=Sin(F2);
L1 :=Sin(L2);
Интересное различие между двумя языками состоит в том, что Ada прини-мает во внимание тип результата функции, в то время как C++ ограничивает-ся формальными параметрами:
|с++
|
C++ |
double sin(double); // Перегрузка sin
double sin(float); // Ошибка, переопределение в области действия
Особый интерес представляет возможность перегрузки стандартных операций, таких как + и в Ada:
|
C++ |
Конечно, вы должны представить саму функцию, реализующую перегруженную операцию для новых типов. Обратите внимание, что синтаксические свойства операций, в частности старшинство, не изменяются. В C++ есть аналогичное средство перегрузки:
|
C++ |
Это совершенно аналогично объявлению функции, за исключением заре-
зервированного ключевого слова operator. Перегружать операции имеет смысл только в том случае, если вновь вводимые операции аналогичны предопределенным, иначе можно запутать тех, кто будет сопровождать программу.
При аккуратном использовании перегрузка позволяет уменьшить длины имен и обеспечить переносимость программы. Она может даже увеличить прозрачность программы, поскольку такие искусственные имена, как fabs, больше не нужны. С другой стороны, перегрузка без разбора может легко нарушить читаемость программы (если одному и тому же имени будет присваиваться слишком много значений). Перегрузка должна быть ограничена подпрограммами, выполняющими аналогичные вычисления, чтобы читатель программы мог понять смысл уже по самому имени подпрограммы.
10.3. Родовые (настраиваемые) сегменты
Массивы, списки и деревья — это структуры данных, в которых могут храниться элементы данных произвольного типа.
Если нужно хранить несколько типов
Если нужно хранить несколько типов одновременно, необходима некоторая форма динамического полиморфизма. Однако если мы работаем только с гомогенными структурами данных, как, например, массив целых чисел или список чисел с плавающей точкой, достаточно статического полиморфизма, чтобы создавать экземпляры программ по шаблонам во времени компиляции.
Рассмотрим подпрограмму, сортирующую массив. Тип элемента массива используется только в двух местах: при сравнении и перестановке элементов.
Сложная обработка индексов делается одинаково для всех типов элементов массива:
type lnt_Array is array(lnteger range <>) of Integer;
procedure Sort(A: lnt_Array) is
|
Ada |
Begin
for I in A'First ..A'Last-1 loop
Min:=l;
for J in I+1 .. A'Last loop
if A(J) < A(Min) then Min := J; end if;
-- Сравнить элементы, используя "<"
end loop;
Temp := A(l); A(l) := A(Min); A(Min) := Temp;
-- Переставить элементы, используя ":="
end loop;
end Sort;
На самом деле даже тип индекса не существенен при программировании этой процедуры, лишь бы он был дискретным типом (например, символьным или целым).
Чтобы получить процедуру Sort для некоторого другого типа элемента, например Character, можно было бы физически скопировать код и сделать необходимые изменения, но это могло бы привести к дополнительным ошибкам. Более того, если бы мы хотели изменить алгоритм, то пришлось бы сделать эти изменения отдельно в каждой копии. В Ada определено средство, называемое родовыми сегментами (generics), которое позволяет программисту задать шаблон подпрограммы, а затем создавать конкретные экземпляры подпрограммы для нескольких разных типов. Хотя в С нет подобного средства, его отсутствие не так серьезно, потому что указатели void, оператор sizeof и указатели на функции позволяют легко запрограммировать «обобщенные», пусть и не такие надежные, подпрограммы.
ние родовых сегментов не гарантирует,
Обратите внимание, что примене ние родовых сегментов не гарантирует, что конкретные экземпляры одной родовой подпрограммы будут иметь общий объектный код; фактически, при реализации может быть выбран независимый объектный код для каждого конкретного случая.
Ниже приведено объявление родовой подпрограммы с двумя родовыми формальными параметрами:
generic
|
Ada |
type ltem_Array is array(lnteger range <>) of Item;
procedure Sort(A: ltem_Array);
Это обобщенное объявление на самом деле объявляет не процедуру, а только шаблон процедуры. Необходимо обеспечить тело процедуры: оно будет написано в терминах родовых параметров:
|
Ada |
Temp, Min: Item;
begin
… -- Полностью совпадает с вышеприведенным
end Sort;
Чтобы получить (подлежащую вызову) процедуру, необходимо конкретизировать родовое объявление, т. е. создать экземпляр, задав родовые фактические параметры:
|
Ada |
type Char_Array is array(lnteger range <>) of Character;
procedure lnt_Sort(A: lnt_Array) is new Sort(lnteger, lnt_Array);
procedure Char_Sort(A: Char_Array) is new Sort(Character, Char_Array);
Это реальные объявления процедур; вместо тела процедуры после объявления следует ключевое слово is, и тем самым запрашивается новая копия обобщенного шаблона.
Родовые параметры — это параметры этапа компиляции, и используются они компилятором, чтобы сгенерировать правильный код для конкретного экземпляра. Параметры образуют контракт между кодом родовой процедуры и ее конкретизацией. Первый параметр Item объявлен с записью (<>). Это означает, что конкретизация программы обещает применить дискретный тип, такой как Integer или Character, а код обещает использовать только операции, допустимые на таких типах. Так как на дискретных типах определены операции отношения, процедура Sort уверена, что «<» допустима.
это предложение контракта, которое говорит:
Второй обобщенный параметр ltem_Array — это предложение контракта, которое говорит: какой бы тип ни был задан для первого параметра, второй параметр должен быть массивом элементов этого типа с целочисленным индексом.
Модель контракта работает в обе стороны. Попытка выполнить арифметическую операцию «+» на значениях типа Item в родовом теле процедуры является ошибкой компиляции, так как существуют такие дискретные типы, как Boolean, для которых арифметические операции не определены. И обратно,родовая процедура не может быть конкретизирована с элементом массива типа запись, потому что операция «<» для записей не определена.
Цель создания модели контракта заключается в том, чтобы позволить программистам многократно применять родовые модули и избавить их от необходимости знать, как реализовано родовое тело процедуры. Уж если родовое тело процедуры скомпилировано, конкретизация может завершиться неуспешно, только если фактические параметры не удовлетворяют контракту. Конкретизация не может быть причиной ошибки компиляции в теле процедуры.
Шаблоны в C++
В языке C++ обобщения реализованы с помощью специального средства — шаблона (template):
template <class ltem_Array> void Sort(ltem_Array parm)
{
…
}
Здесь нет необходимости в явной конкретизации: подпрограмма создается неявно, когда она используется:
typedef int l_Array[100];
typedef char C_Array[100];
l_Array a;
C_Array c;
Sort(a); // Конкретизировать для целочисленных массивов
Sort(c); // Конкретизировать для символьных массивов
Явная конкретизация — это оптимизация, задаваемая программистом по желанию; в противном случае, компилятор сам решает, какие конкретизации необходимо сделать. Шаблоны могут быть конкретизированы только по типам и значениям, или, в более общем случае, по классам (см. гл. 14).
Язык C++ не использует модель контракта, поэтому конкретизация может закончиться неуспешно, вызвав ошибку компиляции в определении шаблона.
и поставку шаблонов как самостоятельных
Это затрудняет производство и поставку шаблонов как самостоятельных компонентов программного обеспечения.
Родовые параметры-подпрограммы в языке Ada
В Ada допускается, чтобы родовые параметры были подпрограммами. Пример программы сортировки может быть написан так:
generic
type Item is private;
type ltem_Array is array(lnteger range <>) of Item;
with function "<"(X, Y: in Item) return Boolean;
procedure Sort(A: ltem_Array);
Контракт теперь расширен тем, что для реализации операции «<» должна быть предоставлена булева функция. А поскольку операция сравнения обеспечена, Item больше не нужно ограничивать дискретными типами, для которых эта операция является встроенной. Ключевое слово private означает, что любой тип, на котором определено присваивание и сравнение на равенство, может применяться при реализации:
type Rec is record . .. end record;
type Rec_Array is array(lnteger range <>) of Rec;
function "<"(R1, R2: in Rec) return Boolean;
procedure Rec_Sort(A: Rec_Array) is new Sort(Rec, Rec_Array, "<");
Внутри подпрограммы Sort присваивание является обычным поразрядным присваиванием для записей, а когда нужно сравнить две записи, вызывается функция «<». Эта обеспеченная программистом функция решит, является ли одна запись меньше другой.
Модель контракта в языке Ada очень мощная: типы, константы, переменные, указатели, массивы, подпрограммы и пакеты (в Ada 95) могут использоваться как родовые параметры.
10.4. Вариантные записи
Вариантные записи используются, когда во время выполнения необходимо интерпретировать значение несколькими разными способами. Ниже перечислены распространенные примеры.
• Сообщения в системе связи и блоках параметров в вызовах операционной системы. Обычно первое поле записи является кодом, значение которого определяет количество и типы остальных полей в записи.
Разнородные структуры данных, такие как
• Разнородные структуры данных, такие как дерево, которое может содержать узлы разных типов.
Чтобы решать проблемы такого рода, языки программирования представляют новый класс типов, называемый вариантными записями, которые имеют альтернативные списки полей. Такая переменная может первоначально содержать значение одного варианта, а позже ей может быть присвоено значение другого варианта с совершенно другим набором полей. Помимо альтернативных могут присутствовать поля, которые являются общими для всех записей этого типа; такие поля обычно содержат код, с помощью которого программа определяет, какой вариант используется на самом деле. Предположим, что мы хотим создать вариантную запись, поля которой могут быть или массивом, или записью:
typedef int Arr[10];
|
C |
float f1;
int i1;
}Rec;
Давайте сначала определим тип, который кодирует вариант:
|
C |
Теперь с помощью типа union (объединение) в С можно создать вариантную запись, которая сама может быть вложена в структуру, включающую общее поле тега, характеризующего вариант:
|
C |
Codes code; /* Общее поле тега */
union { /* Объединение с альтернативными полями */
Агг а; /* Вариант массива */
Rес г; /* Вариант записи */
} data;
} S_Type;
S_Type s;
С точки зрения синтаксиса это всего лишь обычная вложенность записей и массивов внутри других записей. Различие состоит в реализации: полю data выделяется объем памяти, достаточный для самого большого поля массива а или поля записи r (см. рис. 10.1). Поскольку выделяемая память рассчитана на самое большое возможное поле, вариантные записи могут быть чрезвычайно
неэкономны по памяти, если один
неэкономны по памяти, если один вариант очень большой, а другие маленькие:
union {
int a[1000];
|
C |
char c;
}
Избежать этого можно ценой усложнения программирования — использовать указатель на длинные поля.
В основе вариантных записей лежит предположение, что в любой момент времени значимо только одно из полей объединения, в отличие от обычной записи, где все поля существуют одновременно:
if (s.code == Array_Code)
|
C |
else
i = s.data.r.h ; /* Выбор второго варианта */
Основная проблема с вариантными записями состоит в том, что они потенциально могут вызывать серьезные ошибки. Так как конструкция union позволяет программе обращаться к той же самой строке битов различными способами, то возможна обработка значения одного типа, как если бы это было значение какого-либо другого типа (скажем, обращение к числу с плавающей точкой, как к целому). Действительно, программисты, пишущие на языке Pascal, используют вариантные записи, чтобы делать преобразование типов, которое в языке непосредственно не поддерживается.
В вышеупомянутом примере ситуация еще хуже, потому что возможно обращение к ячейкам памяти, которые вообще не содержат никакого значения: поле s.data.r могло бы иметь длину 8 байт для размещения двух чисел, а поле s.data.a — 20 байт для размещения десяти целых чисел. Если в поле s.data.r в данный момент находится запись, то s.data.a[4] не имеет смысла.
В Ada не разрешено использовать вариантные записи, чтобы не разрушать контроль соответствия типов. Поле code, которое мы использовали в примере, теперь является обязательным полем, и называется дискриминантом, а при обращении к вариантным полям проверяется корректность значения дискриминанта. Дискриминант выполняет роль «параметра» типа:
а запись должна быть объявлена
type Codes is (Record_Code, Array_Code);
|
Ada |
record
case Code is
when Record_Code => R: Rec;
when Array_Code => A: Arr;
end case;
end record;
а запись должна быть объявлена с конкретным дискриминантом, чтобы компилятор точно знал, сколько памяти нужно выделить:
|
Ada |
S2: S_Type(Array_Code);
Другая возможность — объявить указатель на вариантную запись и проверять дискриминант во время выполнения:
I Ada type Ptr is access S_Type;
|
Ada |
I:=P.R.I1; --Правильно
I:=P.A(5); -- Ошибка
Первый оператор присваивания правильный, поскольку дискриминант записи P.all — это Record_Code, который гарантирует, что поле R существует; в то же время второй оператор приводит к исключительной ситуации при работе программы, так как дискриминант не соответствует запрошенному полю.
Основное правило для дискриминантов в языке Ada заключается в том, что их можно читать, но не писать, так что нельзя обойти контроль соответствия типов. Это также означает, что память может выделяться в точном соответствии с выбранным вариантом, в отличие от обычного выделения для самого большого варианта.
Неограниченные записи в Ada
В дополнение к ограниченным записям, вариант которых при создании переменной фиксирован, Ada допускает объявление неограниченных записей (unconstrained records), для которых допустимо во время выполнения безопасное с точки зрения контроля типов присваивание, хотя записи относятся к разным вариантам:
S1, S2: S_Type; -- Неограниченные записи
S1 := (Record_Code, 4.5);
S2 := (Array_Code, 1..10 => 17);
S1 := S2; -- Присваивание S1 другого варианта
Два правила гарантируют, что контроль
-- S2 больше, чем S1 !
Два правила гарантируют, что контроль соответствия типов продолжает работать:
• Для дискриминанта должно быть задано значение по умолчанию, чтобы гарантировать, что первоначально в записи есть осмысленный дискриминант:
type S_Type (Code: codes: = Record_Code) is ...
• Само по себе поле дискриминанта не может быть изменено. Допустимо только присваивание допустимого значения всей записи, как показано в примере.
Существуют две возможные реализации неограниченных записей. Можно создавать каждую переменную с размером максимального варианта, чтобы помещался любой вариант. Другая возможность — неявно использовать динамическую память из кучи. Если присваиваемое значение больше по размерам, то память освобождается и запрашивается большая порция. В большинстве реализаций выбран первый метод: он проще и не требует нежела- тельных в некоторых приложениях неявных обращений к менеджеру кучи.
10.5. Динамическая диспетчеризация
Предположим, что каждый вариант записи S_Type должен быть обработан cобственной подпрограммой. Нужно использовать case-оператор, чтобы пе-pейти (dispatch) в соответствующую подпрограмму. Рассмотрим «диспетчерскую» процедуру:
procedure Dispatch(S: S_Type) is
|
Ada |
case S.Code is
when Record_Code => Process_Rec(S);
when Array_Code => Process_Array(S);
end case;
end Dispatch;
Предположим далее, что при изменении программы в запись необходимо до-бавить дополнительный вариант. Сделать изменения в программе нетрудно: бавить код к типу Codes, добавить вариант в case-оператор процедуры Dispatch и добавить новую подпрограмму обработки. Насколько легко сделать эти изменения, настолько они могут быть проблематичными в больших сис-темах, потому что требуют, чтобы исходный код существующих, хорошо про-веренных компонентов программы был изменен и перекомпилирован.
Кроме тогo, вероятно, необходимо сделать
Кроме тогo, вероятно, необходимо сделать повторное тестирование, чтобы гаранти-ровать, что изменение глобального типа перечисления не имеет непредусмот-ренных побочных эффектов.
Решением является размещение «диспетчерского» кода так, чтобы он был частью системы на этапе выполнения, поддерживающей язык, а не явно за-проограммированным кодом, как показано выше. Это называется динамиче-ским полиморфизмом, так как теперь можно вызвать общую программу Process(S), а привязку вызова конкретной подпрограммы отложить до этапа выполнения, когда станет известен текущий тег S. Этот полиморфизм под-держивается виртуальными функциями (virtual functions) в C++ и подпрограм-мами с class-wide-параметрами в Ada 95 (см. гл. 14).
10.6. Упражнения
1. Почему C++ не использует тип результата, чтобы различать перегруженные функции?
2. Какие задачи ставит перегрузка для компоновщика?
3. В C++ операции «++» и «--» могут быть как префиксными, так и постфиксными. Какова «подноготная» этой перегрузки, и как C++ справляется с этими операциями?
4. Ни Ada, ни C++ не позволяют с помощью перегрузки изменять старшинство или ассоциативность операций; почему?
5. Напишите шаблон программы сортировки на C++.
6. Напишите родовую программу сортировки на Ada и используйте ее для сортировки массива записей.
7. Первая родовая программа сортировки определила тип элемента (Item) как (О). Можно ли использовать Long_integer в конкретизации этой процедуры? А что можно сказать относительно Float?
8. Напишите программу, которая поддерживает разнородную очередь, то есть очередь, узлы которой могут содержать значения нескольких типов. Каждый узел будет вариантной записью с альтернативными полями для булевых, целочисленных и символьных значений.
Ошибка во время выполнения программы
Глава 11
Исключительные ситуации
11.1. Требования обработки исключительных ситуаций
Ошибка во время выполнения программы называется исключительной ситуацией или просто исключением (exception). Когда программы исполнялись не интерактивно (offline), соответствующая реакция на исключительную ситуацию состояла в том, чтобы просто напечатать сообщение об ошибке и завершить выполнение программы. Однако реакция на исключение в интерактивной среде не может быть ограничена сообщением, а должна также включать восстановление, например возврат к той точке, с которой пользователь может повторить вычисление или, по крайней мере, выбрать другой вариант. Программное обеспечение, которое используется в таких встроенных системах, как системы управления летательными аппаратами, должно выполнять восстановление при ошибках без вмешательства человека. Обработка исключений до недавнего времени, как правило, не поддерживалась в языках программирования; использовались только средства операционной системы. В этом разделе будут описаны некоторые механизмы обработки исключений, которые существуют в современных языках программирования.
Восстановление при ошибках не дается даром. Всегда есть затраты на дополнительные структуры данных и алгоритмы, необходимые для идентификации и обработки исключений. Кроме того, часто господствует точка зрения, что код обработки исключений сам является компонентом программы и может содержать ошибки, вызывающие более серьезные проблемы, чем первоначальное исключение! К тому же чрезвычайно трудно идентифицировать ситуации, приводящие к ошибке, и тестировать код обработки исключений, потому что сложно, а иногда и невозможно, создать ситуации, приводящие к ошибке.
Какие свойства делают средства обработки исключений хорошими?
В случае отсутствия исключения издержки
• В случае отсутствия исключения издержки должны быть очень небольшими.
• Обработка исключения должна быть легкой в использовании и безопасной.
Первое требование важнее, чем это может показаться. Поскольку мы предполагаем, что исключительные ситуации, как правило, не возникают, издержки для прикладной программы должны быть минимальны. При наступлении исключительной ситуации издержки на ее обработку обычно не считаются существенными. Суть второго требования в том, что, поскольку исключения происходят нечасто, программирование реакции на них не должно требовать больших усилий; само собой разумеется, что обработчик исключения не должен использовать конструкции, которые могут привести к ошибке.
Одно предупреждение для программиста: обработчик исключений не является заменой условного оператора. Если ситуация может возникать, это не является ошибкой и должно быть явно запрограммировано. Например, вероятность того, что такие структуры данных, как список или дерево, окажутся пустыми, весьма велика, и эту ситуацию необходимо явно проверять, используя условный оператор:
|
Ada |
С другой стороны, переполнение стека или потеря значимости в операциях с плавающей точкой встречается очень редко и почти наверняка указывает на ошибку в вычислениях.
В качестве элементарной обработки исключений в некоторых языках пользователю дана возможность определять блок кода, который будет выполнен перед завершением программы. Это полезно для наведения порядка (закрытия файлов и т.д.) перед выходом из программы. В языке С средство setjmp/longjmp позволяет пользователю задать дополнительные точки внутри программы, в которые обработчик исключений может возвращаться. Этого типа обработки исключений достаточно, чтобы гарантировать, что программа «изящно» завершится или перезапустится, но он недостаточно гибок для детализированной обработки исключений.
