в широко распространенный язык, каким
Компилятор для Р-кода был решающим фактором в превращении языка Pascal в широко распространенный язык, каким он является сегодня.
Язык логического программирования Prolog (см. гл. J7) рассматривался вначале как язык, пригодный только для интерпретации. Дэвид Уоррен (David Warren) создал первый настоящий компилятор для языка Prolog, описав абстрактную машину (абстрактная машина Уоррена, или WAM), которая управляла основными структурами данных, необходимыми для выполнения программы на языке. Как компиляцию Prolog в WAM-программы, так и компиляцию WAM-программы в машинный код проделать не слишком трудно; достижение Уоррена состояло в том, что он сумел между двух уровней определить правильный промежуточный уровень — уровень WAM. Многие исследования по компиляции языков логического программирования опирались на WAM.
Похоже, что споры о различиях между компиляторами и интерпретаторами не имеют большого практического значения. При сравнении сред программирования особое внимание следует уделять надежности, правильной компиляции, высокой производительности, эффективной генерации объектного кода, хорошим средствам отладки и т.д., а не технологическим средствам создания самой среды.
3.11. Упражнения
1. Изучите документацию используемого вами компилятора и перечислите оптимизации, которые он выполняет. Напишите программы и проверьте получающийся в результате объектный код на предмет оптимизации.
2. В какой информации от компилятора и от компоновщика нуждается отладчик?
3. Запустите профилировщик и изучите, как он работает.
4. Как можно написать собственный простой инструментарий для тестирования? В чем заключается влияние автоматизированного тестирования на проектирование программы?
5. AdaS — написанный на языке Pascal интерпретатор для подмножества Ada. Он работает, компилируя исходный код в Р-код и затем выполняя Р-код. Изучите AdaS-программу (см.
В программировании этот термин используется
приложение А) и опишите Р-ма-шину.
2 Основные понятия
Глава 4
Элементарные типы данных
4.1. Целочисленные типы
Слово «целое» (integer) в математике обозначает неограниченную, упорядоченную последовательность чисел:
...,-3, -2,-1,0,1,2,3,...
В программировании этот термин используется для обозначения совсем другого — особого типа данных. Вспомним, что тип данных — это множество значений и набор операций над этими значениями. Давайте начнем с определения множества значений типа Integer (целое).
Для слова памяти мы можем определить множество значений, просто интерпретируя биты слова как двоичные значения. Например, если слово из 8 битов содержит последовательность 10100011, то она интерпретируется как:
(1 х 27) + (1 х 25) + (1 х 21) + (1 х 2°) = 128 + 32 + 2 + 1 = 163
Диапазон возможных значений — 0.. 255 или в общем случае 0.. 2В - 1 для слова из В битов. Тип данных с этим набором значений называется unsigned integer (целое без знака), а переменная этого типа может быть объявлена в языке С как:
unsigned intv;
Обратите внимание, что число битов в значении этого типа может быть разным для разных компьютеров.
Сегодня чаще всего встречается размер слова в 32 бита, и целое (без знака) находится в диапазоне 0.. 232 - 1 к 4 х 109. Таким образом, набор математических целых чисел неограничен, в то время как целочисленные типы имеют конечный диапазон значений.
Поскольку тип unsigned integer не может представлять отрицательные числа, он часто используется для представления значений, считываемых внешними устройствами.
Например, при опросе температурного датчика поступает 10 битов информации; эти целые без знака в диапазоне 0.. 1023 нужно будет затем преобразовать в обычные (положительные и отрицательные) числа. Целые числа без знака также используются для представления символов (см. ниже). Их не следует использовать для обычных вычислений, потому что большинство компьютерных команд работает с целыми числами со знаком, и компилятор, возможно, будет генерировать дополнительные команды для операций с целыми без знака.
Диапазон значений переменной может быть
Диапазон значений переменной может быть таким, что значения не поместятся в одном слове или займут только часть слова. Чтобы указать разные целочисленные типы, можно добавить спецификаторы длины:
unsigned int v1 ; /* обычное целое */ [с]
unsigned short int v2; /* короткое целое */
unsigned long int v3; /* длинное целое */
В языке Ada наряду с обычным типом Integer встроены дополнительные типы, например Long_integer (длинное целое). Фактическая интерпретация спецификаторов длины, таких как long и short, различается для различных компиляторов; некоторые компиляторы могут даже давать одинаковую интерпретацию двум или нескольким спецификаторам.
В математике для представления чисел со знаком используется специальный символ «-», за которым следует обычная запись абсолютного значения числа. Компьютеру с таким представлением работать неудобно. Поэтому большинство компьютеров представляет целые числа со знаком в записи, называющейся дополнением до двух *. Положительное число представляется старшим нулевым битом и следующим за ним обычным двоичным представлением значения. Из этого вытекает, что самое большое положительное целое число, которое может быть представлено словом из w битов, не превышает 2W-1 - 1.
Для того чтобы получить представление числа -п по двоичному представлению В = b1b2...bwчисла n:
• берут логическое дополнение В, т. е. заменяют в каждом b ноль на единицу, а единицу на ноль,
• прибавляют единицу.
Например, представление -1, -2 и -127 в виде 8-разрядных слов получается так:
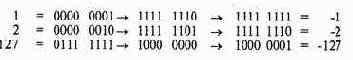
У отрицательных значений в старшем бите всегда будет единица.
Дополнение до двух удобно тем, что при выполнении над такими представлениями операций обычной двоичной целочисленной арифметики получается правильное представление результата:
что строку битов 1000 0000
(-!)-! = -2
1111 1111-00000001 = 1111 1110
Отметим, что строку битов 1000 0000 нельзя получить ни из какого положительного значения. Она представляет значение -128, тогда как соответствующее положительное значение 128 нельзя представить как 8-разрядное число. Необходимо учитывать эту асимметрию в диапазоне типов integer, особенно при работе с типами short.
Альтернативное представление чисел со знаками — дополнение до единицы, в котором представление значения -n является просто дополнением п. В этом случае набор значений симметричен, но зато есть два представления для нуля: 0000 0000 называется положительным нулем, а 1111 1111 называется отрицательным нулем.
Если в объявлении переменной синтаксически не указано, что она без знака (например, unsigned), то по умолчанию она считается целой со знаком:
I
nt i; /* Целое со знаком в языке С */
I: Integer; -- Целое со знаком в языке Ada
Целочисленные операции
К целочисленным операциям относятся четыре основных действия: сложение, вычитание, умножение и деление. Их можно использовать для составления выражений:
а + b/с - 25* (d - е)
К целочисленным операциям применимы обычные математические правила старшинства операций; для изменения порядка вычислений можно использовать круглые скобки.
Результат операции над целыми числами со знаком не должен выходить за диапазон допустимых значений, иначе произойдет переполнение, как рассмотрено ниже. Для целых чисел без знака используется циклическая арифметика. Если short int хранится в 16-разрядном слове, то:
|
с |
i = 65535; /* Наибольшее допустимое значение*/
i = i + 1; /*Циклическая арифметика, i = 0 */
Разработчики Ada 83 сделали ошибку,
Разработчики Ada 83 сделали ошибку, не включив в язык целые без знака. Ada 95 обобщает концепцию целых чисел без знака до модульных типов, которые являются целочисленными типами с циклической арифметикой по произвольному модулю. Обычный байт без знака можно объявить как:
|
Ada |
тогда как модуль, не равный двум, можно использовать для хеш-таблиц или случайных чисел:
|
Ada |
Обратите внимание, что модульные типы в языке Ada переносимы, так как частью определения является только циклический диапазон, а не размер представления, как в языке С.
Деление
В математике в результате деления двух целых чисел а/b получаются два значения: частное q и остаток r, такие что:
а = q * b + r
Так как результатом арифметического выражения в программах является единственное
значение, то для получения частного используют оператор «/», а для получения остатка применяют другой оператор (в языке С это «%», а в Ada — rem). Выражение 54/10 дает значение 5, и мы говорим, что результат операции был усечен (truncated). В языке Pascal для целочисленного деления используется специальная операция div.
При рассмотрении отрицательных чисел определение целочисленного деления не столь тривиально. Чему равно выражение -54/10: -5 или -6? Другими словами, до какого значения делается усечение: до меньшего («более отрицательного») или до ближайшего к нулю? Один вариант — это усечение в сторону нуля, поскольку, чтобы удовлетворить соотношение для целочисленного деления, достаточно просто сменить знак остатка:
-54 = -5*10 + (-4)
Однако существует и другая математическая операция, взятие по модулю (modulo), которая соответствует округлению отрицательных частных до меньшего («более отрицательного») значения:
-54 = -6* 10+ 6
-54 mod 10 = 6
Арифметика по модулю используется всякий раз, когда арифметические операции выполняются над конечными диапазонами, например над кодами с исправлением ошибок в системах связи.
С зависит от реализации, поэтому
Значение операций «/» и «%» в языке С зависит от реализации, поэтому программы, использующие эти целочисленные операции, могут оказаться непереносимыми. В Ada операция «/» всегда усекает в сторону нуля. Операция rem возвращает остаток, соответствующий усечению в сторону нуля, в то время как операция mod возвращает остаток, соответствующий усечению в сторону минус бесконечности.
Переполнение
Говорят, что операция приводит к переполнению, если она дает результат, который выходит за диапазон допустимых значений. Следующие рассуждения для ясности даются в терминах 8-разрядных целых чисел.
Предположим, что переменная i типа signed integer имеет значение 127 и что мы увеличиваем i на 1. Компьютер просто прибавит единицу к целочисленному представлению 127:
0111 1111+00000001 = 10000000
и получит -128. Это неправильный результат, и ошибка вызвана переполнением. Переполнение может приводить к странным ошибкам:
|
C |
Если происходит переполнение выражения j*k, верхняя граница может оказаться отрицательной и цикл не будет выполнен.
Предположите теперь, что переменные a, b и с имеют значения 90, 60 и 80, соответственно. Выражение (а - b + с) вычисляется как 110, потому что (а - b) дает 30, и затем при сложении получается 110. Однако оптимизатор для вычисления выражения может выбрать другой порядок, (а + с - b), давая неправильный ответ, потому что сложение (а + с) дает значение 170, что вызывает переполнение. Если вам в средней школе говорили, что сложение является коммутативным и ассоциативным, то речь шла о математике, а не о программировании!
В некоторых компиляторах можно задать режим проверки на переполнение каждой целочисленной операции, но это может привести к чрезмерным издержкам времени выполнения, если обнаружение переполнения не делается аппаратными средствами. Теперь, когда большинство компьютеров использует 32-разрядные слова памяти, целочисленное переполнение встречается редко, но вы должны знать о такой возможности и соблюдать осторожность, чтобы не попасть в ловушки, продемонстрированные выше.
торые компьютеры имеют команды для
Реализация
Целочисленные значения хранятся непосредственно в словах памяти. Неко торые компьютеры имеют команды для вычислений с частями слов или даже отдельными байтами. Компиляторы для этих компьютеров обычно помещают short int в часть слова, в то время как компиляторы для компьютеров, которые распознают только полные слова, реализуют целочисленные типы int и short int одинаково. Тип long int обычно распределяется в два слова, чтобы получить больший диапазон значений.
Сложение и вычитание компилируются непосредственно в соответствующие команды. Умножение также превращается в одну команду, но выполняется значительно дольше, чем сложение и вычитание. Умножение двух слов, хранящихся в регистрах R1 и R2, дает результат длиной в два слова и требует для хранения двух регистров. Если регистр, содержащий старшее значение, — не ноль, то произошло переполнение.
Для деления требуется, чтобы компьютер выполнил итерационный алгоритм, аналогичный «делению в столбик», выполняемому вручную. Это делается аппаратными средствами, и вам не нужно беспокоиться о деталях, но, если для вас важна эффективность, деления лучше избегать.
Арифметические операции выполняются для типа long int более чем вдвое дольше, нежели операции для int. Причина в том, что нужны дополнительные команды для «распространения» переноса, который может возникать, из слова младших разрядов в слово старших.
4.2. Типы перечисления
Языки программирования типа Fortran и С
описывают данные в терминах компьютера. Данные реального мира должны быть явно отображены на типы данных, которые существуют на компьютере, в большинстве случаев на один из целочисленных типов. Например, если вы пишете программу для управления нагревателем, вы могли бы использовать переменную dial для хранения текущей позиции регулятора. Предположим, что реальная шкала имеет четыре позиции: off (выключено), low (слабо), medium (средне), high (сильно). Как бы вы объявили переменную и обозначили позиции? Поскольку компьютер не имеет команд, которые работают со словами памяти, имеющими только четыре значения, для объявления переменной вы выберете тип integer, а для обозначения позиций четыре конкретных целых числа (скажем 1, 2, 3, 4):
что при использовании целых чисел
|
C |
if (dial < 4) dial++; /* Увеличить уровень нагрева*/
Очевидно, что при использовании целых чисел программу становится трудно читать и поддерживать. Чтобы понять код программы, вам придется написать обширную документацию и постоянно в нее заглядывать. Чтобыулучшить программу, можно прежде всего задокументировать подразумеваемые значения внутри самой программы:
#define Off 1
|
C |
#define Medium 3
#define High 4
int dial;
if(dial<High)dial++;
Однако улучшение документации ничего не дает для предотвращения следующих проблем:
|
C |
dial = High + 1; /* Нераспознаваемое переполнение*/
dial = dial * 3; /* Бессмысленная операция*/
Другими словами, представление шкалы с четырьмя позициями в виде целого числа позволяет программисту присваивать значения, которые выходят за допустимый диапазон, и выполнять команды, бессмысленные для реального объекта. Даже если программист не создаст преднамеренно ни одну из этих проблем, опыт показывает, что они часто появляются в результате отсутствия I взаимопонимания между членами группы разработчиков программы, опеча- ток и других ошибок, типичных при создании сложных систем.
Решение состоит в том, чтобы разрешить разработчику программы созда- вать новые типы, точно соответствующие тем объектам реального мира, которые нужно моделировать. Рассматриваемая здесь короткая упорядоченная последовательность значений настолько часто встречается, что современные языки программирования поддерживают создание типов, называемых типами — перечислениями (enumiration types)*. В языке Ada вышеупомянутый пример выглядел бы так:
Перед тем как подробно объяснить
Ada type Heat is (Off, Low, Medium, High);
Dial: Heat;
|
Ada |
if Dial < High then Dial := Heat'Succ(DialJ;
Dial:=-1; —Ошибка
Dial := Heat'Succ(High); -- Ошибка
Dial := Dial * 3; - Ошибка
Перед тем как подробно объяснить пример, обратим внимание на то, что в языке С есть конструкция, на первый взгляд точно такая же:
|
C |
Однако переменные, объявленные с типом Heat, — все еще целые, и ни одна из вышеупомянутых команд не считается ошибкой (хотя компилятор может выдавать предупреждение):
Heat dial;
|
C |
dial = High + 1; /* Не является ошибкой! */
dial = dial * 3; /* Не является ошибкой! */
Другими словами, конструкция enum* — всего лишь средство документирования, более удобное, чем длинные строки define, но она не создает новый тип.
К счастью, язык C++ использует более строгую интерпретацию типов перечисления и не допускает присваивания целочисленного значения переменной перечисляемого типа; указанные три команды здесь будут ошибкой. Однако значения перечисляемых типов могут быть неявно преобразованы в целые числа, поэтому контроль соответствия типов не является полным. К сожалению, в C++ не предусмотрены команды над перечисляемыми типами, поэтому здесь нет стандартного способа увеличения переменной этого типа. Вы можете написать свою собственную функцию, которая берет результат целочисленного выражения и затем явно преобразует его к типу перечисления:
|
C++ |
Обратите внимание на неявное преобразование dial в целочисленный тип, вслед за которым происходит явное преобразование результата обратно в Heat.
поэтому они могут быть использованы
Операции «++» и «--» над целочисленными типами в C++ можно перегрузить (см. раздел 10.2), поэтому они могут быть использованы для определения операций над типами перечисления, которые синтаксически совпадают с операциями над целочисленными типами.
В языке Ada определение типа приводит к созданию нового типа Heat. Значения этого типа не являются целыми числами. Любая попытка выйти за диапазон допустимых значений или применить целочисленные операции будет отмечена как ошибка. Если вы случайно нажмете не на ту клавишу и введете Higj вместо High, ошибка будет обнаружена, потому что тип содержит именно те четыре значения, которые были объявлены. Если бы вы использовали один из типов integer, 5 было бы допустимым целым, как и 4.
Перечисляемые типы аналогичны целочисленным: вы можете объявлять переменные и параметры этих типов. Однако набор операций, которые могутвыполняться над значениями этого типа, ограничен. В него входят присваивание (:=), равенство (=) и неравенство (/=). Поскольку набор значений в объявлении интерпретируется как упорядоченная последовательность, для него определены операции отношений (<,>,>=,<=).
В языке Ada для заданного Т перечисляемого типа и значения V типа Т определены следующие функции, называемые атрибутами:
• T'First возвращает первое значение Т.
• Т'Last возвращает последнее значение Т.
• T'Succ(V) возвращает следующий элемент V.
• T'Pred(V) возвращает предыдущий элемент V.
• T'Pos(V) возвращает позицию V в списке значений Т.
• T'Val(l) возвращает значение I-й позиции в Т.
Атрибуты делают программу устойчивой к изменениям: при добавлении значений к типу перечисления или переупорядочивании значений циклы и индексы остаются неизменными:
for I in Heat'First.. Heat'Last - 1 loop
|
Ada |
end loop;
He каждый разработчик языка «верует» в перечисляемые типы. В языке Eiffel их нет по следующим причинам:
Желательно было сделать язык как
• Желательно было сделать язык как можно меньшего объема.
• Можно получить тот же уровень надежности, используя контрольные утверждения (раздел 11.5).
• Перечисляемые типы часто используются с вариантными записями (раздел 10.4); при правильном применении наследования (раздел 14.3) потребность в перечисляемых типах уменьшается.
Везде, где только можно, следует предпочитать типы перечисления обычным целым со списками заданных констант; их вклад в надежность программы невозможно переоценить. Программисты, работающие на С, не имеют преимуществ контроля соответствия типов, как в Ada и C++, и им все же следует использовать enum, чтобы улучшить читаемость программы.
Реализация
Я расскажу вам по секрету, что значения перечисляемого типа представляются в компьютере в виде последовательности целых чисел, начинающейся с нуля. Контроль соответствия типов в языке Ada делается только во время компиляции, а такие операции как «<» представляют собой обычные целочисленные операции.
Можно потребовать, чтобы компилятор использовал нестандартное представление перечисляемых типов. В языке С это задается непосредственно в определении типа:
|
C |
тогда как в Ada используется спецификация представления: __
|
Ada |
type Heat is (Off, Low, Medium, High);
for Heat use (Off = >1, Low = >2, Medium = >4, High = >8);
4.3. Символьный тип
Хотя первоначально компьютеры были изобретены для выполнения операций над числами, скоро стало очевидно, что не менее важны прикладные программы для обработки нечисловой информации. Сегодня такие приложения, как текстовые процессоры, образовательные программы и базы данных, возможно, по количеству превосходят математические прикладные программы. Даже такие математические приложения, как финансовое программное обеспечение, нуждаются в обработке текста для ввода и вывода.
С точки зрения разработчика программного
С точки зрения разработчика программного обеспечения обработка текста чрезвычайно сложна из-за разнообразия естественных языков и систем записи. С точки зрения языков программирования обработка текста относительно проста, так как подразумевается, что в языке набор символов представляет собой короткую, упорядоченную последовательность значений, то есть символы могут быть определены перечисляемым типом. Фактически, за исключением языков типа китайского и японского, в которых используются тысячи символов, достаточно 128 целых значений со знаком или 256 значений без знака, представимых восемью разрядами.
Различие в способе определения символов в языках Ada и С аналогично различию в способе определения перечисляемых типов. В Ada есть встроенный перечисляемый тип: __
|
Ada |
и все обычные операции над перечисляемыми типами (присваивание, отношения, следующий элемент, предыдущий элемент и т.д.) применимы к символам. В Ada 83 для типа Character допускались 128 значений, определенных в американском стандарте ASCII, в то время как в Ada 95 принято представление этого типа байтом без знака, так что доступно 256 значений, требуемых международными стандартами.
В языке С тип char — это всего лишь ограниченный целочисленный тип, и допустимы все следующие операторы, поскольку char и int по сути одно и то же:
char с;
int i;
с='А' + 10; /* Преобразует char в int и обратно */
|
C |
с = i; /* Преобразует int в char */
В языке C++ тип char отличается от целочисленного, но поскольку допустимы преобразования в целочисленный и обратно, то перечисленные операторы остаются допустимыми.
Для неалфавитных языков могут быть определены 16-разрядные символы. Они называются wcharj в С и C++, и Wide_Character в Ada 95.
что отличает символы от обычных
Единственное, что отличает символы от обычных перечислений или целых, — специальный синтаксис ('А') для набора значений и, что более важно, специальный синтаксис для массивов символов, называемых строками (раздел 5.5).
4.4. Булев тип
Boolean — встроенный перечисляемый тип в языке Ada:
type Boolean is (False, True);
Тип Boolean имеет очень большое значение, потому что:
• операции отношения (=, >, и т.д.) — это функции, которые возвращают значение булева типа;
• условный оператор проверяет выражение булева типа;
• операции булевой алгебры (and, or, not, xor) определены для булева типа.
В языке С нет самостоятельного булева типа; вместо этого используются целые числа в следующей интерпретации:
• Операции отношения возвращают 1, если отношение выполняется, и 0 в противном случае.
• Условный оператор выполняет переход по ветке false (ложь), если вычисление целочисленного выражения дает ноль, и переход по ветке true (истина) в противном случае.
В языке С существует несколько методов введения булевых типов. Одна из возможностей состоит в определении типа, в котором будет разрешено объявление функций с результатом булева типа:
typedef enum {false, true} bool;
|
C |
if (data-valid (x, y)). . .
но это применяется, конечно, только для документирования и удобочитаемости, потому что такие операторы, как:
|
C |
b = b + 56; /* Сложить 56 с «true» ?? */
все еще считаются приемлемыми и могут приводить к скрытым ошибкам.
В языке C++ тип bool является встроенным целочисленным типом (не типом перечисления) с неявными взаимными преобразованиями между ненулевыми значениями и литералом true, а также между нулевыми значениями и false. Программа на С с bool, определенным так, как показано выше, может быть скомпилирована на C++ простым удалением typedef.
С лучше не использовать неявное
Даже в языке С лучше не использовать неявное преобразование целых в булевы, а предпочитать явные операторы равенства и неравенства:
|
C |
if (a + b-2)... /* ...такойвариант.*/
if (а + b ! = О)... /* Этот вариант понятнее, чем */
if (! (а + b))... /*... такой вариант. */
Наконец, отметим, что в языке С применяется так называемое укороченное (short-circuit) вычисление выражений булевой алгебры. Это мы обсудим в разделе 6.2.
4.5. Подтипы
В предыдущих разделах мы обсудили целочисленные типы, позволяющие выполнять вычисления в большом диапазоне значений, которые можно представить в слове памяти, и перечисляемые типы, которые работают с меньшими диапазонами, но не позволяют выполнять арифметические вычисления. Однако во многих случаях нам хотелось бы делать вычисления в небольших диапазонах целых чисел. Например, должен существовать какой-нибудь способ, позволяющий обнаруживать такие ошибки как:
Temperature: Integer;
Temperature := -280; -- Ниже абсолютного нуля!
Compass-Heading: Integer;
Compass-Heading := 365; - Диапазон компаса 0..359 градусов!
Предположим, что мы попытаемся определить новый класс типов:
type Temperatures is Integer range -273 .. 10000; - - He Ada!
type Headings is Integer range 0 .. 359; -- He Ada!
Это решает проблему проверки ошибок, вызванных значениями, выходящими за диапазон типа, но остается вопрос: являются эти два типа разными или нет? Если это один и тот же тип, то
Temperature * Compass_Heading
является допустимым арифметическим выражением на типе целое; если нет, то должно использоваться преобразование типов.
На практике полезны обе эти интерпретации. В вычислениях, касающихся физического мира, удобно использовать значения разных диапазонов.
в таблицах или порядковые номера
С другой стороны, индексы в таблицах или порядковые номера не требуют вычислений с разными типами: имеет смысл запросить следующий индекс в таблице, а не складывать индекс таблицы с порядковым номером. Для этих двух подходов к определению типов в языке Ada есть два разных средства.
Подтип (subtype) — это ограничение на существующий тип. Дискретные типы (целочисленные и перечисляемые) могут иметь ограничение диапазона.
subtype Temperatures is Integer range -273 .. 10000;
Temperature: Temperatures;
subtype Headings is Integer range 0 .. 359;
Compass_Heading: Headings;
Тип значения подтипа S тот же, что и тип исходного базового типа Т; здесь базовый как у Temperatures, так и у Headings — тип Integer. Тип определяется во время компиляции. Значение подтипа имеет то же самое представление, что и значение базового типа, и допустимо везде, где требуется значение базового типа:
Temperature * Compass_Heading
это допустимое выражение, но операторы:
Temperature := -280;
Compass-Heading := 365;
приводят к ошибке, потому что значения выходят за диапазоны подтипов. Нарушения диапазона подтипа выявляются во время выполнения.
Подтипы могут быть определены на любом типе, для которого его исходный диапазон может быть разумно ограничен:
subtype Upper-Case is Character range 'A'.. 'Z';
U: Upper-Case;
C: Character;
U := 'a'; -- Ошибка, выход за диапазон
С := U; -- Всегда правильно
U := С; -- Может привести к ошибке
Подтипы важны для определения массивов, как это будет рассмотрено в разделе 5.4. Кроме того, именованный подтип можно использовать для упрощения многих операторов:
if С in Upper-Case then ... - Проверка диапазона
for C1 in Upper-Case loop ... — Границы цикла
4.6. Производные типы
Вторая интерпретация отношения между двумя аналогичными типами состоит в том, что они представляют разные типы, которые не могут использоваться вместе.
В языке Ada такие типы
В языке Ada такие типы называются производными (derived) типами и обозначаются в определении словом new:
type Derived_Dharacter is new Character;
C: Character;
D: Derived_Character;
С := D: -- Ошибка, типы разные
Когда один тип получен из другого типа, называемого родительским (parent) типом, он наследует копию набора значений и копию набора операций, но типы остаются разными. Однако всегда допустимо явное преобразование между типами, полученными друга из друга:
D := Derived_Character(C); -- Преобразование типов
С := Character(D); -- Преобразование типов
Можно даже задать другое представление для производного типа; преобразование типов будет тогда преобразованием между двумя представлениями (см. раздел 5.8).
Производный тип может включать ограничение на диапазон значений родительского типа:
type Upper_Case is new Character range 'A'.. 'Z';
U: Upper_Case;
C: Character;
С := Character(U); -- Всегда правильно
U := Upper_Case(C); -- Может привести к ошибке
Производные типы в языке Ada 83 реализуют слабую версию наследования (weak version of inheritance), которая является центральным понятием объектно-ориентированных языков (см. гл. 14). Пересмотренный язык Ada 95 реализует истинное наследование (true inheritance), расширяя понятие производных типов; мы еще вернемся к их изучению.
Целочисленные типы
Предположим, что мы определили следующий тип:
type Altitudes is new Integer range 0 .. 60000;
Это определение работает правильно, когда мы программируем моделирование полета на 32-разрядной рабочей станции. Что случается, когда мы передадим программу на 16-разрядный контроллер, входящий в состав бортовой электроники нашего самолета? Шестнадцать битов могут представлять целые числа со знаком только до значения 32767.
Таким образом, использование производного типа
Таким образом, использование производного типа было бы ошибкой (так же, как подтипа или непосредственно Integer) и нарушило бы программную переносимость, которая является основной целью языка Ada.
Чтобы решать эту проблему, можно задать производный целый тип без явного указания базового родительского типа:
type Altitudes is range 0 .. 60000;
Компилятор должен выбрать представление, которое соответствует требуемому диапазону — integer на 32-разрядном компьютере и Long_integer на 16-разрядном компьютере. Это уникальное свойство позволяет легко писать на языке Ada переносимые программы для компьютеров с различными длинами слова.
Недостаток целочисленных типов состоит в том, что каждое определение создает новый тип, и нельзя писать вычисления, которые используют разные типы без преобразования типа:
I: Integer;
A: Altitude;
А := I; -- Ошибка, разные типы
А := Altitude(l); -- Правильно, преобразование типов
Таким образом, существует неизбежный конфликт:
• Подтипы потенциально ненадежны из-за возможности писать смешанные выражения и из-за проблем с переносимостью.
• Производные типы безопасны и переносимы, но могут сделать программу трудной для чтения из-за многочисленных преобразований типов.
4.7. Выражения
Выражение может быть очень простым, состоящим только из литерала (24, V, True) или переменной, но может быть и сложной комбинацией, включающей операции (в том числе вызовы системных или пользовательских функций). В результате вычисления выражения получается значение.
Выражения могут находиться во многих местах программы: в операторах присваивания, в булевых выражениях условных операторов, в границах for-циклов, параметрах процедур и т. д. Сначала мы обсудим само выражение, а затем операторы присваивания.
Значение литерала — это то, что он обозначает; например, значение 24 — целое число, представляемое строкой битов 0001 1000.
содержимое ячейки памяти, которую она
Значение переменной V — содержимое ячейки памяти, которую она обозначает. Обратите внимание на возможную путаницу в операторе:
V1 :=V2;
V2 — выражение, значение которого является содержимым некоторой ячейки памяти. V1 — адрес ячейки памяти, в которую будет помещено значение V2.
Более сложные выражения содержат функцию с набором параметров или операцию с операндами. Различие, в основном, в синтаксисе: функция с параметрами пишется в префиксной нотации sin (x), тогда как операция с операндами пишется в инфиксной нотации а + b. Поскольку операнды сами могут быть выражениями, можно создавать выражения какой угодно сложности:
a + sin(b)*((c-d)/(e+34))
В префиксной нотации порядок вычисления точно определен за исключением порядка вычисления параметров отдельной функции:
max (sin (cos (x)), cos (sin (y)))
Можно написать программы, результат которых зависит от порядка вычисления параметров функции (см. раздел 7.3), но такой зависимости от порядка вычисления следует избегать любой ценой, потому что она является источником скрытых ошибок при переносе программы и даже при ее изменении.
Инфиксной нотации присущи свои проблемы, а именно проблемы старшинства и ассоциативности. Почти все языки программирования придерживаются математического стандарта назначения мультипликативным операциям («*», «/») более высокого старшинства, чем операциям аддитивным («+», «-»), старшинство других операций определяется языком. Крайности реализованы в таких языках, как АР L, в котором старшинство вообще не определено (даже для арифметических операций), и С, где определено 15 уровней старшинства! Частично трудность изучения языка программирования связана с необходимостью привыкнуть к стилю, который следует из правил старшинства.
Примером неинтуитивного назначения старшинства служит язык- Pascal. Булева операция and рассматривается как операция умножения с высоким старшинством, тогда как в большинстве других языков, аналогичных С, ее приоритет ниже, чем у операций отношения.
является ошибочным, потому что это
Следующий оператор:
|
pascal |
является ошибочным, потому что это выражение интерпретируется
|
Pascal |
и синтаксис оказывается неверен.
Значение инфиксного выражения зависит также от ассоциативности операций, т. е. от того, как группируются операции одинакового старшинства: слева направо или справа налево. В большинстве случаев, но не всегда, это не имеет значения (кроме возможного переполнения, как рассмотрено в разделе 4.1). Однако значение выражения, включающего целочисленное деление, может зависеть от ассоциативности из-за усечения:
|
C |
i = i * j / k; /* результат равен 1 2 или 1 4? */
В целом, бинарные операции группируются слева направо, так что рассмотренный пример компилируется как:
|
C |
в то время как унарные операции группируются справа налево: !++i в языке С вычисляется, как ! (++i).
Все проблемы старшинства и ассоциативности можно легко решить с помощью круглых скобок; их использование ничего не стоит, поэтому применяйте их при малейшем намеке на неоднозначность интерпретации выражения.
В то время как старшинство и ассоциативность определяются языком, порядок вычисления обычно отдается реализаторам для оптимизации. Например, в следующем выражении:
(а + Ь) + с + (d + е)
не определено, вычисляется а + b раньше или позже d + е, хотя с будет просуммировано с результатом а + b раньше, чем с результатом d + е. Порядок может играть существенную роль, если выражение вызывает побочные эффекты, т. е. если при вычислении подвыражения происходит обращение к функции, которая изменяет глобальную переменную.
Реализация
Реализация выражения, конечно, зависит от реализации операций, используемых в выражении. Однако стоит обсудить некоторые общие принципы.
Выражения вычисляются изнутри наружу; например, а * (b + с) вычисляется так:
в форме, которая делает порядок
load R1,b
load R2, с
add R1 , R2 Сложить b и с, результат занести в R1
load R2, а
mult R1.R2 Умножить а на b + с, результат занести в R1
Можно написать выражение в форме, которая делает порядок вычисления явным:
явным:
bс + а
Читаем слева направо: имя операнда означает загрузку операнда, а знак операции означает применение операции к двум самым последним операндам и замену всех трех (двух операндов и операции) результатом. В этом случае складываются b и с; затем результат умножается на а.
Эта форма называется польской инверсной записью (reverse polish notation — RPN) и может использоваться компилятором. Выражение переводится в RPN, и затем компилятор вырабатывает команды для каждого операнда и операции, читая RPN слева направо..
Для более сложного выражения, скажем:
(а + b) * (с + d) * (е + f)
понадобилось бы большее количество регистров для хранения промежуточных результатов: а + b, с + d и т. д. При увеличении сложности регистров не хватит, и компилятору придется выделить неименованные временные пере менные для сохранения промежуточных результатов. Что касается эффектив ности, то до определенной точки увеличение сложности выражения дает лучший результат, чем использование последовательности операторов присваивания, так как позволяет избежать ненужного сохранения промежуточных результатов в памяти. Однако такое улучшение быстро сходит на нет из-за необходимости заводить временные переменные, и в некоторой точке компилятор, возможно, вообще не сможет обработать сложное выражение.
Оптимизирующий компилятор сможет определить, что подвыражение а+b в выражении
(а + b) * с + d * (а + b)
нужно вычислить только один раз, но сомнительно, что он сможет распознать это, если задано
(а + b) * с + d * (b + а)
Если общее подвыражение сложное, возможно, полезнее явно присвоить его переменной, чем полагаться на оптимизатор.
компилятор сделает умножение один раз
Другой вид оптимизации — свертка констант. В выражении:
2.0* 3.14159* Radius
компилятор сделает умножение один раз во время компиляции и сохранит результат. Нет смысла снижать читаемость программы, производя свертку констант вручную, хотя при этом можно дать имя вычисленному значению:
|
C |
Two_PI: constant := 2.0 * PI;
Circumference: Float := Two_PI * Radius;
4.8. Операторы присваивания
Смысл оператора присваивания:
переменная := выражение;
состоит в том, что значение выражения должно быть помещено по адресу памяти, обозначенному как переменная. Обратите внимание, что левая часть оператора также может быть выражением, если это выражение можно вычислить как адрес:
|
Ada |
Выражение, которое может появиться в левой части оператора присваивания, называется l-значением; константа, конечно, не является 1-значением. Все выражения дают значение и поэтому могут появиться в правой части оператора присваивания; они называются r-значениями. В языке обычно не определяется порядок вычисления выражений слева и справа от знака присваивания. Если порядок влияет на результат, программа не будет переносимой.
В языке С само присваивание определено как выражение. Значение конструкции
переменная = выражение;
такое же, как значение выражения в правой части. Таким образом,
|
C |
v1 = v2 = v3 = e;
означает присвоить (значение) е переменной v3, затем присвоить результат переменной v2, затем присвоить результат переменной v1 и игнорировать конечный результат.
В Ada присваивание является оператором, а не выражением, и многократные присваивания не допускаются. Многократное объявление
V1.V2.V3: Integer :=Е;
рассматривается как сокращенная запись для
|
Ada |
V2: Integer := Е;
V3: Integer := Е;
а не как многократное присваивание.
С использует тот факт, что
Хотя стиль программирования языка С использует тот факт, что присваивание является выражением, этого, вероятно, следует избегать как источник скрытых ошибок программирования. Весьма распространенный класс ошибок вызван тем, что присваивание («=») путают с операцией равенства («==»). В следующем операторе:
|
C |
программист, возможно, хотел просто сравнить i и j, не обратив внимания, что значение i изменяется оператором присваивания. Некоторые С-компиляторы расценивают это как столь плохой стиль программирования, что выдают предупреждающее сообщение.
Полезным свойством языка С является комбинация операции и присваивания:
|
C |
v = v + е; /* такого оператора. */
Операции с присваиванием особенно важны в случае сложной переменной, включающей индексацию массива и т.д. Комбинированная операция не только экономит время набора на клавиатуре, но и позволяет избежать ошибки, если v написано не одинаково с обеих сторон от знака «=». И все же комбинированные присваивания — всего лишь стилистический прием, так как оптимизирующий компилятор может удалить второе вычисление адреса v.
Можно предотвратить присваивание значения объекту, объявляя его как константу.
const int N = 8; /* Константа в языке С */
N: constant Integer := 8; — Константа в языке Ada
Очевидно, константе должно быть присвоено начальное значение.
Есть различие между константой и статическим значением (static value), которое известно на этапе компиляции:
procedure P(C: Character) is
С1 : constant Character := С;
|
Ada |
Begin
…
case C is
when C1 => -- Ошибка, не статическое значение
when C2 => -- Правильно, статическое значение
ние не может быть изменено
…
end case;
…
end P;
Локальная переменная С1 — это постоянный объект, в том смысле что значе ние не может быть изменено внутри процедуры, даже если ее значение будет разным при каждом вызове процедуры. С другой стороны, варианты выбора в case должны быть известны во время компиляции. В отличие от языка С язык C++ рассматривает константы как статические:
|
C++ |
int a[N]; //Правильно в C++, но не в С
Реализация
После того как вычислено выражение в правой части присваивания, чтобы сохранить его значение в памяти, нужна как минимум одна команда. Если выражение в левой части сложное (индексация массива и т.д.), то понадобятся дополнительные команды для вычисления нужного адреса памяти.
Если длина значения правой части превышает одно слово, потребуется несколько команд, чтобы сохранить значение в случае, когда компьютер не поддерживает операцию блочного копирования, которая позволяет копировать последовательность заданных слов памяти, указав начальный адрес источника, начальный адрес приемника и число копируемых слов.
4.9. Упражнения
1. Прочитайте документацию вашего компилятора и выпишите, какая точность используется для разных целочисленных типов.
2. Запишите 200 + 55 = 255 и 100-150 = -50 в дополнительном коде.
3. Пусть а принимает все значения в диапазонах 50 .. 56 и -56 .. -50, и пусть b равно 7 или -7. Каковы возможные частные q и остатки г при делении а на b? Используйте оба определения остатка (обозначенные rem и mod в Ada) и отобразите результаты в графической форме. Подсказка: если используется rem, r будет иметь знак а; если используется mod, r будет иметь тот же знак, что и b.
4. Что происходит, когда вы выполняете следующую С-программу на компьютере, который сохраняет значения short int в 8 битах, а значения int в 16 битах?
short int i: [с]
int j = 280;
for (i = 0; i <j; i++) printf("Hello world");
Как бы вы реализовали атрибут
5. Как бы вы реализовали атрибут T'Succ (V) языка Ada, если используется нестандартное представление перечисляемого типа?
6. Что будет печатать следующая программа? Почему?
|
C |
int j = 5;
if (i&j)printf("Hello world");
if (i.&&j) printf("Goodbye world");
7. Каково значение i после выполнения следующих операторов?
|
C |
int a[2] = { 10,11};
i=a[i++];
8. Языки С и C++ не имеют операции возведения в степень; почему?
9. Покажите, как могут использоваться модульные типы в Ada 95 и типы целого без знака в С для представления множеств. Насколько переносимым является ваше решение? Сравните с типом множества (set) в языке Pascal.
Глава 5
Составные типы данных
Языки программирования, включая самые первые, поддерживают составные типы данных. С помощью массивов представляются вектора и матрицы, используемые в математических моделях реального мира. Записи используются при обработке коммерческих данных для представления документов различного формата и хранения разнородных данных.
Как и для любого другого типа, для составного типа необходимо описать наборы значений и операций над этими значениями. Кроме того, необходимо решить: как они строятся из элементарных значений, и какие операции можно использовать, чтобы получить доступ к компонентам составного значения? Число встроенных операций над составными типами обычно невелико, поэтому большинство операций нужно явно программировать из операций, допустимых для компонентов составного типа.
Поскольку массивы являются разновидностью записей, мы начнем обсуждение с записей (в языке С они называются структурами).
5.1. Записи
Значение типа запись (record) состоит из набора значений других типов, называемых компонентами (components — Ada), членами (members — С) или полями (fields —Pascal). При объявлении типа каждое поле получает имя и тип. Следующее объявление в языке С описывает структуру с четырьмя компонентами: одним — типа строка, другим — заданным пользователем перечислением и двумя компонентами целого типа:
После того как определен тип
typedef enum {Black, Blue, Green, Red, White} Colors;
|
C |
char model[20];
Colors color;
int speed;
int fuel;
} Car_Data;
Аналогичное объявление в языке Ada таково:
type Colors is (Black, Blue, Green, Red, White);
|
Ada |
record
Model: String(1..20);
Color: Colors:
Speed: Integer;
Fuel: Integer;
end record;
После того как определен тип записи, могут быть объявлены объекты (переменные и константы) этого типа. Между записями одного и того же типа допустимо присваивание:
|
C |
с1 =с2;
а в Ada (но не в С) также можно проверить равенство значений этого типа:
С1, С2, СЗ: Car_Data;
|
Ada |
С1 =СЗ;
end if;
Поскольку тип — это набор значений, можно было бы подумать, что всегда можно обозначить* значение записи. Удивительно, но этого вообще нельзя сделать; например, язык С допускает значения записи только при инициализации. В Ada, однако, можно сконструировать значение типа запись, называемое агрегатом (aggregate), просто задавая значение правильного типа для каждого поля. Связь значения с полем может осуществляться по позиции внутри записи или по имени поля:
|
Ada |
С1 := (-Peugeot-, Red, C2.Speed, CS.Fuel);
C2 := (Model=>-Peugeot", Speed=>76,
Fuel=>46, Color=>White);
Это чрезвычайно важно, потому что компилятор выдаст сообщение об ошибке, если вы забудете включить значение для поля; а при использовании отдельных присваиваний легко просто забыть одно из полей:
|
Ada |
--Забыли С1.Color
С1.Speed := C2.Speed;
С1.Fuel := CS.Fuel;
Можно выбрать отдельные поля записи,
Можно выбрать отдельные поля записи, используя точку и имя поля:
|
C |
Будучи выбранным, поле записи становится обычной переменной или значением типа поля, и к нему применимы все операции, соответствующие этому типу.
Имена полей записи локализованы внутри определения типа и могут повторно использоваться в других определениях:
typedef struct {
float speed; /* Повторно используемое имя поля */
|
C |
Performance p;
Car_Data с;
p.speed = (float) с.speed; /* To же самое имя, другое поле*/
Отдельные записи сами по себе не очень полезны; их значение становится очевидным, только когда они являются частью более сложных структур, таких как массивы записей или динамические структуры, создаваемые с помощью указателей (см. раздел 8.2).
Реализация
Значение записи представляется некоторым числом слов в памяти, достаточным для того, чтобы вместить все поля. На рисунке 5.1 показано размещение записи Car_Data. Поля обычно располагаются в порядке их появления в определении типа записи.
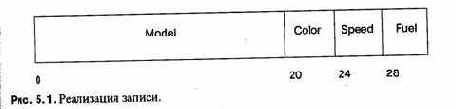
Доступ к отдельному полю очень эффективен, потому что величина смещения каждого поля от начала записи постоянна и известна во время компиляции. Большинство компьютеров имеет способы адресации, которые позволяют добавлять константу к адресному регистру при декодировании команды. После того как начальный адрес записи загружен в регистр, для доступа к полям лишние команды уже не нужны:
load R1.&C1 Адрес записи
load R2,20(R1) Загрузить второе поле
load R3,24(R1) Загрузить третье поле
Так как для поля иногда нужен объем памяти, не кратный размеру слова, компилятор может
«раздуть» запись так, чтобы каждое поле заведомо находилось на границе слова, поскольку доступ к не выровненному на границу слову гораздо менее эффективен. На 16-разрядном компьютере такое определение типа, как:
к выделению четырех слов для
typedef struct {
|
C |
int f2; /* 2 байта*/
char f3; /* 1 байт, пропустить 1 байт */
int f4; • /* 2 байта*/
};
может привести к выделению четырех слов для каждой записи таким образом, чтобы поля типа int были выровнены на границу слова, в то время как следующие определения:
typedef struct { [с]
|
C |
int f4; /* 2 байта*/
charfl ; /Мбайт*/
char f3; /* 1 байт */
потребовали бы только трех слов. При использовании компилятора, который плотно упаковывает поля, можно улучшить эффективность, добавляя фиктивные поля для выхода на границы слова. В разделе 5.8 описаны способы явного распределения полей. В любом случае, никогда не привязывайте программу к конкретному формату записи, поскольку это сделает ее непереносимой.
5.2. Массивы
Массив — это запись, все поля которой имеют один и тот же тип. Кроме того, поля (называемые элементами или компонентами) задаются не именами, а позицией внутри массива. Преимуществом этого типа данных является возможность эффективного доступа к элементу по индексу. Поскольку все элементы имеют один и тот же тип, можно вычислить положение отдельного элемента, умножая индекс на размер элемента. Используя индексы, легко найти отдельный элемент массива, отсортировать или как-то иначе реорганизовать элементы.
Индекс в языке Ada может иметь произвольный дискретный тип, т.е. любой тип, на котором допустим «счет». Таковыми являются целочисленные типы и типы перечисления (включая Character и Boolean):
|
Ada |
type Temperatures is array(Heat) of Float;
Temp: Temperatures;
С ограничивает индексный тип целыми
Язык С ограничивает индексный тип целыми числами; вы указываете, сколько компонентов вам необходимо:
|
C |
float temp[Max];
а индексы неявно изменяются от 0 до числа компонентов без единицы, в данном случае от 0 до 3. Язык C++ разрешает использовать любое константное выражение для задания числа элементов массива, что улучшает читаемость программы:
|
C++ |
float temp [last+ 1];
Компоненты массива могут быть любого типа:
|
C |
Car_Data database [100];
В языке Ada (но не в С) на массивах можно выполнять операции присваивания и проверки на равенство:
type A_Type is array(0..9) of Integer;
|
Ada |
if A = В then A := C; end if;
Как и в случае с записями, в языке Ada для задания значений массивов, т. е. для агрегатов, предоставляется широкий спектр синтаксических возможностей :
|
Ada |
А := (0..4 => 1 , 5..9 => 2); -- Половина единиц, половина двоек
А := (others => 0); -- Все нули
В языке С использование агрегатов массивов ограничено заданием начальных значений.
Наиболее важная операция над массивом — индексация, с помощью которой выбирается элемент массива. Индекс, который может быть произвольным выражением индексного типа, пишется после имени массива:
type Char_Array is array(Character range 'a'.. 'z') of Boolean;
|
Ada |
C: Character:= 'z';
A(C):=A('a')andA('b');
Другой способ интерпретации массивов состоит в том, чтобы рассматривать их как функцию, преобразующую индексный тип в тип элемента. Язык Ada (подобно языку Fortran, но в отличие от языков Pascal и С) поощряет такую точку зрения, используя одинаковый синтаксис для обращений к функции и для индексации массива. То есть, не посмотрев на объявление, нельзя сказать, является А(1) обращением к функции или операцией индексации массива.
в том, что структура данных
Преимущество общего синтаксиса в том, что структура данных может быть первоначально реализована как массив, а позже, если понадобится более сложная структура данных, массив может быть заменен функцией без изменения формы обращения. Квадратные скобки вместо круглых в языках Pascal и С применяются в основном для облегчения работы компилятора.
Записи и массивы могут вкладываться друг в друга в произвольном порядке, что позволяет создавать сложные структуры данных. Для доступа к отдельному компоненту такой структуры выбор поля и индексация элемента должны выполняться по очереди до тех пор, пока не будет достигнут компонент:
typedef int A[1 0]; /* Тип массив */
|
C |
А а; /* Массив внутри записи */
char b;
} Rec;
Rec r[10]; /* Массив записей с массивами типа int внутри */
int i,j,k;
k = r[i+l].a[j-1]; /* Индексация, затем выбор поля,затем индексация */
/* Конечный результат — целочисленное значение */
Обратите внимание, что частичный выбор и индексация в сложной структуре данных дают значение, которое само является массивом или записью:
|
C |
r[i] Запись, содержащая массив целых чисел
r[i].a Массив целых чисел
r[i].a[j] Целое
и эти значения могут использоваться в операторах присваивания и т.п.
5.3. Массивы и контроль соответствия типов
Возможно, наиболее общая причина труднообнаруживаемых ошибок — это индексация, которая выходит за границы массива:
inta[10],
|
C |
i<= 10; i
a[i] = 2*i;
Цикл будет выполнен и для i = 10, но последним элементом массива является а[9].
Причина распространенности этого типа ошибки
Причина распространенности этого типа ошибки в том, что индексные выражения могут быть произвольными, хотя допустимы только индексы, попадающие в диапазон, заданный в объявлении массива. Самая простая ошибка может привести к тому, что индекс получит значение, которое выходит за этот диапазон. Серьезность возникающей ошибки в том, что присваивание a[i] (если i выходит за допустимый диапазон) вызывает изменение некоторой случайной ячейки памяти, возможно, даже в области операционной системы. Даже если аппаратная защита допускает изменение данных только в области вашей собственной программы, ошибку будет трудно найти, так как она проявится в другом месте, а именно в командах, которые используют измененную память.
Рассмотрим случай, когда числовая ошибка заставляет переменную speed получить значение 20 вместо 30:
|
C |
speed = (х+у)/3; /*Вычислить среднее! */
Проявлением ошибки является неправильное значение speed, и причина (деление на 3 вместо 2) находится здесь же, в команде, которая вычисляет speed. Это проявление непосредственно связано с ошибкой и, используя контрольные точки или точки наблюдения, можно быстро локализовать ошибку. В следующем примере:
inta[10];
|
C |
for(i = 0;i<= 10; i ++)
a[i] = 2*j;
переменная speed является жертвой того факта, что она была чисто случайно объявлена как раз после а и, таким образом, была изменена совершенно посторонней командой. Вы можете днями прослеживать вычисление speed и не найти ошибку.
Решение подобных проблем состоит в проверке операции индексации над массивами с тем, чтобы гарантировать соблюдение границ. Любая попытка превысить границы массива рассматривается как нарушение контроля соответствия типов. Впервые проверка индексов была предложена в языке Pascal:
|
pascal |
A: A_Type;
A[10]:=20; (*Ошибка*)
При контроле соответствия типов ошибка
При контроле соответствия типов ошибка обнаруживается сразу же, на своем месте, а не после того, как она «затерла» некоторую «постороннюю» память; целый класс серьезных ошибок исчезает из программ. Точнее, такие ошибки становятся ошибками этапа компиляции, а не ошибками этапа выполнения программы.
Конечно, ничего не дается просто так, и существуют две проблемы контроля соответствия типов для массивов. Первая — увеличение времени выполнения, которое является ценой проверок (мы обсудим это в одном из следующих разделов). Вторая проблема — это противоречие между способом, которым мы работаем с массивами, и способом работы контроля соответствия типов. Рассмотрим следующий пример:
|
pascal |
type B_Type= array[0..8] of Real;
А: А_Туре: (* Переменные-массивы *)
В: В_Туре;
procedure Sort(var P: А_Туре); (* Параметр-массив *)
sort(A); (* Правильно*) sort(B); (* Ошибка! *)
Два объявления типов определяют два различных типа. Тип фактического параметра процедуры должен соответствовать типу формального параметра, поэтому кажется, что необходимы две разные процедуры Sort, каждая для своего типа. Это не соответствует нашему интуитивному понятию массива и операций над массивом, потому что при тщательном программировании процедур, аналогичных Sort, их делают не зависящими от числа элементов в массиве; границы массива должны быть просто дополнительными параметрами. Обратите внимание, что эта проблема не возникает в языках Fortran или С потому, что в них нет параметров-массивов! Они просто передают адрес начала массива, а программист отвечает за правильное определение и использование границ массива.
В языке Ada изящно решена эта проблема. Тип массива в Ada определяется исключительно сигнатурой, т. е.
и типом элемента. Такой тип
типом индекса и типом элемента. Такой тип называется типом массива без ограничений. Чтобы фактически объявить массив, необходимо добавить к типу ограничение индекса:
|
Ada |
-- Объявление типа массива без ограничений
А: А_Туре(0..9); — Массив с ограничением индекса
В: А_Туре(0..8); — Массив с ограничением индекса
Сигнатура А_Туре — одномерный массив с индексами типа integer и компонентами типа Float; границы индексов не являются частью сигнатуры.
Как и в языке Pascal, операции индексации полностью контролируются:
|
Ada |
В(9) := 20.5; -- Ошибка, индекс изменяется в пределах 0..8
Важность неограниченных массивов становится очевидной, когда мы рассматриваем параметры процедуры. Так как тип (неограниченного) массива-параметра определяется только сигнатурой, мы можем вызывать процедуру с любым фактическим параметром этого типа независимо от индексного ограничения:
|
Ada |
— Тип параметра: неограниченный массив
Sort(A); -- Типом А является А_Туре
Sort(B); -- Типом В также является А_Туре
Теперь возникает вопрос: как процедура Sort может получить доступ к границам массива? В языке Pascal границы были частью типа и таким образом были известны внутри процедуры. В языке Ada ограничения фактического параметра-массива автоматически передаются процедуре во время выполнения и могут быть получены через функции, называемые атрибутами. Если А произвольный массив, то:
Использование атрибутов массива позволяет программисту
• A'First — индекс первого элемента А.
• A'Last — индекс последнего элемента А.
• A'Length — число элементов в А.
• A'Range — эквивалент A'First.. A'Last.
Например:
|
Ada |
for I in P'Range loop
for J in 1+1 .. P'Lastloop
end Sort;
Использование атрибутов массива позволяет программисту писать чрезвычайно устойчивое к изменениям программное обеспечение: любое изменение границ массива автоматически отражается в атрибутах.
Подводя итог, можно сказать: контроль соответствия типов для массивов — мощный инструмент для улучшения надежности программ; однако определение границ массива не должно быть частью статического определения типа.
5.4. Подтипы массивов в языке Ada
Подтипы, которые мы обсуждали в разделе 4.5, определялись добавлением ограничения диапазона к дискретному типу (перечисляемому или целочисленному). Точно так же подтип массива может быть объявлен добавлением к типу неограниченного массива ограничения индекс'.
type A_Type is array(lnteger range о) of Float;
subtype Line is A_Type(1 ..80);
L, L1, L2: Line;
Значение этого именованного подтипа можно использовать как фактический параметр, соответствующий формальному параметру исходного неограниченного типа:
Sort(L);
В любом случае неограниченный формальный параметр процедуры Sort динамически ограничивается фактическим параметром при каждом вызове процедуры.
Приведенные в разделе 4.5 рассуждения относительно подтипов применимы и здесь. Массивы разных подтипов одного и того же типа могут быть присвоены друг другу (при условии, что они имеют одинаковое число элементов), но массивы разных типов не могут быть присвоены друг другу без явного преобразования типов.
В Ada есть мощные конструкции,
Определение именованного подтипа — всего лишь вопрос удобства.
В Ada есть мощные конструкции, называемые сечениями (slices) и сдвигами
(sliding), которые позволяют выполнять присваивания над частями массивов. Оператор
L1(10..15):=L2(20..25);
присваивает сечение одного массива другому, сдвигая индексы, пока они не придут в соответствие. Сигнатуры типов проверяются во время компиляции, тогда как ограничения проверяются во время выполнения и могут быть динамическими:
L1(I..J):=L2(l*K..M+2);
Проблемы, связанные с определениями типа для массивов в языке Pascal, заставили разработчиков языка Ada обобщить решение для массивов изящной концепцией подтипов: отделить статическую спецификацию типа от ограничения, которое может быть динамическим.
5.5. Строковый тип
В основном строки — это просто массивы символов, но для удобства программирования необходима дополнительная языковая поддержка. Первое требование: для строк нужен специальный синтаксис, в противном случае работать с массивами символов было бы слишком утомительно. Допустимы оба следующих объявления, но, конечно, первая форма намного удобнее:
char s[]= "Hello world";
chars[] = {‘H’,’e’,’l’,’o’,’ ‘,’w’,’o’,’r’,’l’,’d’,’/0’};
Затем нужно найти некоторый способ работы с длиной строки. Вышеупомянутый пример уже показывает, что компилятор может определить размер I строки без явного его задания программистом. Язык С использует соглаше-I ние о представлении строк, согласно которому первый обнаруженный нулевой байт завершает строку. Обработка строк в С обычно содержит цикл while вида:
|
C |
Основной недостаток этого метода состоит в том, что если завершающий ноль почему-либо отсутствует, то память может быть затерта, так же как и при любом выходе за границы массива:
Копировать set. Какой длины s?
|
C |
для нулевого байта*/
chart[11];
strcpy(t, s); /* Копировать set. Какой длины s? */
Другие недостатки этого метода:
• Строковые операции требуют динамического выделения и освобождения памяти, которые относительно неэффективны.
• Обращения к библиотечным строковым функциям приводят к повторным вычислениям длин строк.
• Нулевой байт не может быть частью строки.
Альтернативное решение, используемое некоторыми диалектами языка Pascal, состоит в том, чтобы включить явный байт длины как неявный нулевой символ строки, чья максимальная длина определяется при объявлении:
S:String[10];
|
Pascal |
writeln(S);
S:='Hello';
writeln(S);
Сначала программа выведет «Hello worl», так как строка будет усечена до объявленной длины. Затем выведет «Hello», поскольку writeln принимает во внимание неявную длину. К сожалению, это решение также небезупречно, потому что возможно непосредственное обращение к скрытому байту длины и затирание памяти:
|
Pascal |
В Ada есть встроенный тип неограниченного массива, называемый String, со следующим определением:
|
Ada |
Каждая строка должна быть фиксированной длины и объявлена с индексным ограничением:
|
Ada |
В отличие от языка С, где вся обработка строк выполняется с использованием библиотечных процедур, подобных strcpy, в языке Ada над строками допускаются такие операции, как конкатенация «&», равенство и операции отношения, подобные «<». Поскольку строго предписан контроль соответствия типов, нужно немного потренироваться с атрибутами, чтобы заставить все заработать:
Т должна быть вычислена до
|
Ada |
S2: constant String := "world";
T: String(1 .. S1 'Length + 1 + S2'Length) := S1 & ' ' & S2;
Put(T); -- Напечатает Hello world
Точная длина Т должна быть вычислена до того, как выполнится присваивание! К счастью, Ada поддерживает атрибуты массива и конструкцию для создания подмассивов (называемых сечениями — slices), которые позволяют выполнять такие вычисления переносимым способом.
Ada 83 предоставляет базисные средства для определения строк нефиксированной длины, но не предлагает необходимых библиотечных подпрограмм для обработки строк. Чтобы улучшить переносимость, в Ada 95 определены стандартные библиотеки для всех трех категорий строк: фиксированных, изменяемых (как в языке Pascal) и динамических (как в С).
5.6. Многомерные массивы
Многомерные матрицы широко используются в математических моделях физического мира, и многомерные массивы появились в языках программирования начиная с языка Fortran. Фактически есть два способа определения многомерных массивов: прямой и в качестве сложной структуры. Мы ограничимся обсуждением двумерных массивов; обобщение для большей размерности делается аналогично.
Прямое определение двумерного массива в языке Ada можно дать, указав два индексных типа, разделяемых запятой:
type Two is
|
Ada |
T:Two('A'..'Z', 1 ..10); I: Integer;
C: Character;
T('XM*3):=T(C,6);
Как показывает пример, две размерности не обязательно должны быть одного и того же типа. Элемент массива выбирают, задавая оба индекса.
Второй метод определения двумерного массива состоит в том, чтобы определить тип, который является массивом массивов:
|
Ada |
type Array_of_Array is array (Character range <>) of l_Array;
в том, что можно получить
T:Array_of_Array('A1..>ZI);
I: Integer;
С: Character;
T('X')(I*3):=T(C)(6);
Преимущество этого метода в том, что можно получить доступ к элементам второй размерности (которые сами являются массивами), используя одну операцию индексации:
|
Ada |
Недостаток же в том, что для элементов второй размерности должны быть заданы
ограничения до того, как эти элементы будут использоваться для определения первой размерности.
В языке С доступен только второй метод и, конечно, только для целочисленных индексов:
|
C |
а[1] = а[2]; /* Присвоить массив из 20 элементов */
Язык Pascal не делает различий между двумерным массивом и массивом массивов; так как границы считаются частью типа массива, это не вызывает никаких проблем.
5.7. Реализация массивов
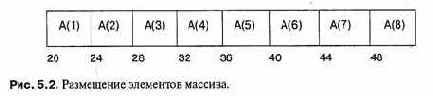
При реализации элементы массива размещаются в памяти последовательно. Если задан массив А, то адрес его элемента A(l) есть (см. рис. 5.2.):
addr (А) + size (element) * (/ - A.'First)
Например: адрес А(4) равен 20 + 4 * (4 - 1) = 32.
Сгенерированный машинный код будет выглядеть так:
L
oad R1,l Получить индекс
sub R1,A'First Вычесть нижнюю границу
multi R1 ,size Умножить на размер — > смещение
add R1 ,&А Добавить адрес массива — > адрес элемента
load R2,(R1) Загрузить содержимое
Вы, возможно, удивитесь, узнав, что для каждого доступа к массиву нужно столько команд! Существует много вариантов оптимизации, которые могут улучшить этот код. Сначала отметим, что если A'First — ноль, то нам не нужно вычитать индекс первого элемента; это объясняет, почему разработчики языка С сделали так, что индексы всегда начинаются с нуля.
не ноль, но известен на
Даже если A'First — не ноль, но известен на этапе компиляции, можно преобразовать вычисление адреса следующим образом:
(addr (А) - size (element) * A'First) + (size (element) * i)
Первое выражение в круглых скобках можно вычислить при компиляции, экономя на вычитании во время выполнения. Это выражение будет известно во время компиляции при обычных обращениях к массиву:
|
Ada |
A(I):=A(J);
но не в том случае, когда массив является параметром:
procedure Sort(A: A_Type) is
|
Ada |
…
A(A'First+1):=A(J);
…
end Sort;
Основное препятствие для эффективных операций с массивом — умножение на размер элемента массива. К счастью, большинство массивов имеют простые типы данных, такие как символы или целые числа, и размеры их элементов представляют собой степень двойки. В этом случае дорогостоящая операция умножения может быть заменена эффективным сдвигом, так как сдвиг влево на n эквивалентен умножению на 2". В случае массива записей можно повысить эффективность (за счет дополнительной памяти), дополняя записи так, чтобы их размер был кратен степени двойки. Обратите внимание, что на переносимость программы это не влияет, но само улучшение эффективности не является переносимым: другой компилятор может скомпоновать запись по-другому.
Программисты, работающие на С, могут иногда повышать эффективность обработки массивов, явно программируя доступ к элементам массива с помощью указателей вместо индексов. Следующие определения:
typedef struct {
|
C |
int field;
} Rec;
Rec a[100];
могут оказаться более эффективными (в зависимости от качества оптимизаций в компиляторе) при обращении к элементам массива по указателю:
Rec* ptr;
|
C |
...ptr-> field...;
чем при помощи индексирования:
for(i=0; i<100;i++)
…a[i].field…
Однако такой стиль программирования чреват множеством ошибок; кроме того, такие программы тяжело читать, поэтому его следует применять только в исключительных случаях.
с запятой стоит пустой оператор.
В языке С возможен и такой способ копирования строк:
|
C |
в котором перед точкой с запятой стоит пустой оператор. Если компьютер поддерживает команды блочного копирования, которые перемещают содержимое блока ячеек памяти по другому адресу, то эффективнее будет язык типа Ada, который допускает присваивание массива. Вообще, тем, кто программирует на С, следует использовать библиотечные функции, которые, скорее всего, реализованы более эффективно, чем примитивный способ, показанный выше.
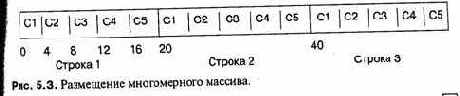
Многомерные массивы могут быть очень неэффективными, потому что каждая лишняя размерность требует дополнительного умножения при вычислении индекса. При работе с многомерными массивами нужно также понимать, как размещены данные. За исключением языка Fortran, все языки хранят двумерные массивы как последовательности строк. Размещение
|
Ada |
показано на рис. 5.3. Такое размещение вполне естественно, поскольку сохраняет идентичность двумерного массива и массива массивов. Если в вычислении перебираются все элементы двумерного массива, проследите, чтобы последний индекс продвигался во внутреннем цикле:
intmatrix[100][200];
|
C |
for (j = 0; j < 200; j++)
m[i][j]=…;
Причина в том, что операционные системы, использующие разбиение на страницы, работают намного эффективнее, когда адреса, по которым происходят обращения, находятся близко друг к другу.
Если вы хотите выжать из С-программы максимальную производительность, можно игнорировать двумерную структуру массива и имитировать одномерный массив:
|
C |
m[]0[i]=…;
Само собой разумеется, что применять такие приемы не рекомендуется, а в случае использования их следует тщательно задокументировать.
Контроль соответствия типов для массива требует, чтобы попадание индекса в границы проверялось перед каждым доступом к массиву.
Издержки этой проверки велики: два
Издержки этой проверки велики: два сравнения и переходы. Компиляторам для языков типа Ada приходится проделывать значительную работу, чтобы оптимизировать команды обработки массива. Основной технический прием — использование доступной информации. В следующем примере:
|
Ada |
if A(I) = Key then ...
индекс I примет только допустимые для массива значения, так что никакая проверка не нужна. Вообще, оптимизатор лучше всего будет работать, если все переменные объявлены с максимально жесткими ограничениями.
Когда массивы передаются как параметры на языке с контролем соответствия типов:
|
Ada |
procedure Sort(A: A_Type) is ...
границы также неявно должны передаваться в структуре данных, называемой дескриптором массива (dope vector) (рис. 5.4). Дескриптор массива содержит
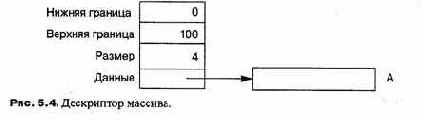
верхнюю и нижнюю границы, размер элемента и адрес начала массива. Как мы видели, это именно та информация, которая нужна для вычисления адресов при индексации массива.
5.8. Спецификация представления
В этой книге неоднократно подчеркивается значение интерпретации программы как абстрактной модели реального мира. Однако для таких программ, как операционные системы, коммуникационные пакеты и встроенное программное обеспечение, необходимо манипулировать данными на физическом уровне их представления в памяти.
Вычисления над битами
В языке С есть булевы операции, которые выполняются побитно над значениями целочисленных типов: «&» (and), «|» (or), «л» (xor), «~» (not).
Булевы операции в Ada — and, or, xor, not — также могут применяться к булевым массивам:
type Bool_Array is array(0..31) of Boolean;
|
Ada |
B2: Bool_Array := (0..15 => False, 16..31 => True);
B1 :=B1 orB2;
Однако само объявление булевых массивов не гарантирует, что они представляются как битовые строки; фактически, булево значение обычно представляется как целое число.
чтобы компилятор упаковывал значения массива
Добавление управляющей команды
|
Ada |
требует, чтобы компилятор упаковывал значения массива как можно плотнее. Поскольку для булева значения необходим только один бит, 32 элемента массива могут храниться в 32-разрядном слове. Хотя таким способом и обеспечиваются требуемые функциональные возможности, однако гибкости, свойственной языку С, достичь не удастся, в частности, из-за невозможности использовать в булевых вычислениях такие восьмеричные или шестнад-цатеричные константы, как OxfOOf OffO. Язык Ada обеспечивает запись для таких констант, но они являются целочисленными значениями, а не булевыми массивами, и поэтому не могут использоваться в поразрядных вычислениях.
Эти проблемы решены в языке Ada 95: в нем для поразрядных вычислений могут использоваться модульные типы (см. раздел 4.1):
|
Ada |
UI,U2: Unsigned_Byte;
U1 :=U1 andU2;
Поля внутри слов
Аппаратные регистры обычно состоят из нескольких полей. Традиционно доступ к таким полям осуществляется с помощью сдвига и маскирования; оператор
field = (i » 4) & 0x7;
извлекает трехбитовое поле, находящееся в четырех битах от правого края слова i. Такой стиль программирования опасен, потому что очень просто сделать ошибку в числе сдвигов и в маске. Кроме того, при малейшем изменении размещения полей может потребоваться значительное изменение программы.
- Изящное решение этой проблемы впервые было сделано в языке Pascal: использовать обычные записи, но упаковывать несколько полей в одно слово. Обычный доступ к полю Rec.Field автоматически переводится компилятором в правильные сдвиг и маску.
В языке Pascal размещение полей в слове явно не задается; в других языках такое размещение можно описать явно. Язык С допускает спецификаторы разрядов в поле структуры (при условии, что поля имеют целочисленный тип):
|
C |
и это позволяет программисту использовать
typedef struct {
int : 3; /* Заполнитель */
int f1 :1;
int f2 :2;

|
C |
int f3 :2;
int : 4; /* Заполнитель */
int f4 :1;
}reg;
и это позволяет программисту использовать обычную форму предложений присваивания (хотя поля и являются частью слова), а компилятору реализовать эти присваивания с помощью сдвигов и масок:
reg r;
|
C |
i = r.f2;
r.f3 = i;
Язык Ada неуклонно следует принципу: объявления типа должны быть абстрактными. В связи с этим спецификации представления (representation specifications) используют свою нотацию и пишутся отдельно от объявления типа. К следующим ниже объявлениям типа:
type Heat is (Off, Low, Medium, High);
type Reg is
|
Ada |
F1: Boolean;
F2: Heat;
F3: Heat;
F4: Boolean;
end record;
может быть добавлена такая спецификация:
|
Ada |
record
F1 at 0 range 3..3;
F2 at Orange 4..5;
F3at 1 range 1..2;
F4at 1 range 7..7;
end record;
Конструкция at определяет байт внутри записи, a range определяет отводимый полю диапазон разрядов, причем мы знаем, что достаточно одного бита для значения Boolean и двух битов для значения Heat. Обратите внимание, что заполнители не нужны, потому что определены точные позиции полей.
Если разрядные спецификаторы в языке С и спецификаторы представления в Ada правильно запрограммированы, то обеспечена безошибочность всех последующих обращений.
Порядок байтов в числах
Как правило, адреса памяти растут начиная с нуля. К сожалению, архитектуры компьютеров отличаются способом хранения в памяти многобайтовых значений. Предположим, что можно независимо адресовать каждый байт и что каждое слово состоит из четырех байтов. В каком виде будет храниться целое число 0x04030201: начиная со старшего конца (big endian), т.
что старший байт имеет меньший
е. так, что старший байт имеет меньший адрес, или начиная с младшего конца (little endian), т. е. так, что младший байт имеет меньший адрес? На рис. 5.6 показано размещение байтов для двух вариантов.
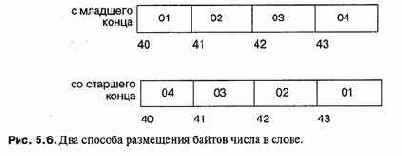
В компиляторах такие архитектурные особенности компьютеров, естественно, учтены и полностью прозрачны (невидимы) для программиста, если он описывает свои данные на должном уровне абстракции.
Однако при использовании спецификаций представления разница между двумя соглашениями может сделать программу непереносимой. В языке Ada 95 порядок битов слова может быть задан программистом, так что для переноса программы, использующей спецификации представления, достаточно заменить всего лишь спецификации.
Производные типы и спецификации представления в языке Ada
Производный тип в языке Ada (раздел 4.6) определен как новый тип, чьи значения и
операции такие же, как у родительского типа. Производный тип может иметь представление, отличающееся от родительского типа. Например, если определен обычный тип Unpacked_Register:
|
Ada |
record
…
end record;
можно получить новый тип и задать спецификацию представления, связанную с производным типом:
|
Ada |
for Packed_Register use
record
…
end record;
Преобразование типов (которое допустимо между любыми типами, полученными друг из друга) вызывает изменение представления, а именно упаковку и распаковку полей слов в обычные переменные:
U: Unpacked_Register;
Р: Packed_Register;
|
Ada |
Р := Packed_Register(U);
Это средство может сделать программы более надежными, потому что, коль скоро написаны правильные спецификации представления, остальная часть программы становится полностью абстрактной.
5.9. Упражнения
Упаковывает ваш компилятор поля записи
1. Упаковывает ваш компилятор поля записи или выравнивает их на границы слова?
2. Поддерживает ли ваш компьютер команду блочного копирования, и использует ли ее ваш компилятор для операций присваивания над массивами и записями?
3. Pascal содержит конструкцию with, которая открывает область видимости имен так, что имена полей записи можно использовать непосредственно:
type Rec =
record
|
Paskal |
Field2: Integer;
end;
R: Rec;
with R do Field 1 := Field2; (* Правильно, непосредственная видимость *)
Каковы преимущества и недостатки этой конструкции? Изучите в Ada конструкцию renames и покажите, как можно получить некоторые аналогичные функциональные возможности. Сравните две конструкции.
4. Объясните сообщение об ошибке, которое вы получаете в языке С при попытке присвоить один массив другому:
|
C |
а1 =а2;
5. Напишите процедуры sort на языках Ada и С и сравните их. Убедитесь, что вы используете атрибуты в процедуре Ada так, что процедура будет обрабатывать массивы с произвольными индексами.
6. Как оптимизирует ваш компилятор операции индексации массива?
7. В языке Icon имеются ассоциативные массивы, называемые таблицами, в которых строка может использоваться как индекс массива:
count["begin"] = 8;
Реализуйте ассоциативные массивы на языках Ada или С.
8. Являются следующие два типа одним и тем же?
|
Ada |
type Array_Type_2 is array(1 ..100) of Float;
Языки Ada и C++ используют эквивалентность имен: каждое объявление типа объявляет новый тип, так что будут объявлены два типа. При структурной эквивалентности (используемой в языке Algol 68) объявления типа, которые выглядят одинаково, определяют один и тот же тип. Каковы преимущества и недостатки этих двух подходов?
В Ada может быть определен
9. В Ada может быть определен массив анонимного типа. Допустимо ли присваивание в следующем примере? Почему?
|
Ada |
А1 :=А2;
Глава 6
Управляющие структуры
Управляющие операторы предназначены для изменения порядка выполнения команд программы. Есть два класса хорошо структурированных управляющих операторов: операторы выбора (if и case), которые выбирают одну из двух или нескольких возможных альтернативных последовательностей выполнения, и операторы цикла (for и while), которые многократно выполняют последовательность операторов.
6.1. Операторы switch и case
Оператор выбора используется для выбора одного из нескольких возможных путей, по которому должно выполняться вычисление (рис. 6.1). Обобщенный оператор выбора называется switch-оператором в языке С и case-onepaтором в других языках.
Switch-оператор состоит из выражения (expression) и оператора (statement) для каждого возможного значения (value) выражения:
switch (expression) {
|
C |
statement_1;
break;
case value_2:
statement_2;
break;
….
}
Выражение вычисляется, и его результат используется для выбора оператора, который будет выполнен; на рис. 6. 1 выбранный оператор представляет путь. Отсюда следует, что для каждого возможного значения выражения должна существовать в точности одна case-альтернатива. Для целочисленного выражения это невозможно, так как нереально написать свой оператор для каждого 32-разрядного целочисленного значения. В языке Pascal case-оператор используется только для типов, которые имеют небольшое число значений, тогда как языки С и Ada допускают альтернативу по умолчанию (default), что позволяет использовать case-оператор даже для таких типов, как Character, которые имеют сотни значений:
|
C |
default_statement;
Если вычисленного значения выражения не
break;
,
Если вычисленного значения выражения не оказывается в списке, то выполняется оператор, заданный по умолчанию (default_statement). В языке С, если альтернатива default отсутствует, по умолчанию подразумевается пустой оператор. Эту возможность использовать не следует, потому что читатель программы не может узнать, подразумевался ли пустой default-оператор, или программист просто забыл задать необходимые операторы.
Во многих случаях операторы для двух или нескольких альтернатив идентичны. В языке С нет специальных средств для этого случая (см. ниже); а в Ada есть обширный набор синтаксических конструкций Для группировки альтернатив:
С: Character;
case С is
|
Ada |
when '0'.. '9' => statement_2;
when '+' | '-' |' *' | '/' =>statement_3;
when others => statement_4;
end case;
В Ada альтернативы представляются зарезервированным ключевым словом when, а альтернатива по умолчанию называется others. Case-альтернативаможет содержать диапазон значений value_1 .. value_2 или набор значений, разделенных знаком «|».
Оператор break в языке С
В языке С нужно явно завершать каждую case-альтернативу оператором break, иначе после него вычисление «провалится» на следующую case-альтернативу. Можно воспользоваться такими «провалами» и построить конструкцию, напоминающую многоальтернативную конструкцию языка Ada:
char с;
switch (с) {
case 'A': case'B': ... case'Z':
statement_1 ;
|
C |
case'O': ... case '9':
statement_2;
break;
case '+'; case '-': case '*': case '/':
statement_3 :
break;
default:
statement_4;
break;
Поскольку каждое значение должно быть явно написано, switch-оператор в языке С далеко не так удобен, как case-оператор в Ada.
оператор должен использоваться для выбора
В обычном программировании «провалы» использовать не стоит:
switch (е) {
casevalue_1:
|
C |
case value_2:
statement_2; /* автоматический провал на statement_2. */
break;
}
Согласно рис. 6.1 switch - оператор должен использоваться для выбора одного из нескольких возможных путей. «Провал» вносит путаницу, потому что при достижении конца пути управление как бы возвращается обратно к началу дерева выбора. Кроме того, с точки зрения семантики не должна иметь никакого значения последовательность, в которой записаны варианты выбора (хотя в смысле эффективности порядок может быть важен). При сопровождении программы нужно иметь возможность свободно изменять существующие варианты выбора или вставлять новые варианты, не опасаясь внести ошибку. Такую программу, к тому же, трудно тестировать и отлаживать: если ошибка прослежена до оператора statement_2, трудно узнать, был оператор достигнут непосредственным выбором или в результате провала. Чем пользоваться «провалом», лучше общую часть (common_code) оформить как процедуру:
switch (e) {
case value_1 :
|
C |
common_code();
break;
case value_2:
common_code();
break;
}
Реализация
Самым простым способом является компиляция case-оператора как последовательности проверок:
compute R1 ,ехрг Вычислить выражение
jump_eq R1,#value_1,L1
jump_eq R1,#value_2 ,L2
… Другие значения
default_statement Команды, выполняемые по
умолчанию
jump End_Case
С точки зрения эффективности очевидно,
L1: statement_1 Команды для statement_1
jump End_Case
L2: statement_2 Команды для statement_2
jump End_Case
… Команды для других операторов
End_Case:
С точки зрения эффективности очевидно, что чем ближе к верхней части оператора располагается альтернатива, тем более эффективен ее выбор; вы можете переупорядочить альтернативы, чтобы извлечь пользу из этого факта (при условии, что вы не используете «провалы»!).
Некоторые case-операторы можно оптимизировать, используя таблицы переходов. Если набор значений выражения образует короткую непрерывную последовательность, то можно использовать следующий код (подразумевается, что выражение может принимать значения от 0 до 3):
compute R1,expr
mult R1,#len_of_addr expr* длина_адреса
add R1 ,&table + адрес_начала_таблицы
jump (R1) Перейти по адресу в регистре R1
table: Таблица переходов
addr(L1)
addr(L2)
addr(L3)
addr(L4)
L1: statement_1
jump End_Case
L2: statement_2
jump End_Case
L3: statement_3
jump End_Case
L4: statement_4
End_Case:
Значение выражения используется как индекс для таблицы адресов операторов, а команда jump осуществляет переход по адресу, содержащемуся в регистре.
Значение выражения обязательно должно лежать
Затраты на реализацию варианта с таблицей переходов фиксированы и невелики для всех альтернатив.
Значение выражения обязательно должно лежать внутри ожидаемого диапазона (здесь от 0 до 3), иначе будет вычислен недопустимый адрес, и произойдет переход в такое место памяти, где может даже не быть выполнимой команды! В языке Ada выражение часто может быть проверено во время компиляции:
|
Ada |
S: Status;
case S is ... -- Имеется в точности четыре значения
В других случаях будет необходима динамическая проверка, чтобы гарантировать, что значение лежит внутри диапазона. Таблицы переходов совместимы даже с альтернативой по умолчанию при условии, что явно заданные варианты выбора расположены непрерывно друг за другом. Компилятор просто вставляет динамическую проверку допустимости использования таблицы переходов; при отрицательном результате проверки вычисляется альтернатива по умолчанию.
Выбор реализации обычно оставляется компилятору, и нет никакой возможности узнать, какая именно реализация используется, без изучения машинного кода. Из документации оптимизирующего компилятора вы, возможно, и узнаете, при каких условиях будет компилироваться таблица переходов. Но даже если вы учтете их при программировании, ваша программа не перестанет быть переносимой, потому что сам case-оператор — переносимый; однако разные компиляторы могут реализовывать его по-разному, поэтому увеличение эффективности не является переносимым.
6.2. Условные операторы
Условный оператор — это частный случай case- или switch-оператора, в котором выражение имеет булев тип. Так как булевы типы имеют только два допустимых значения, условный оператор делает выбор между двумя возможными путями. Условные операторы — это, вероятно, наиболее часто используемые управляющие структуры, поскольку часто применяемые операции отношения возвращают значения булева типа:
С нет булева типа. Вместо
|
C |
statement_1;
else
statement_2;
Как мы обсуждали в разделе 4.4, в языке С нет булева типа. Вместо этого применяются целочисленные значения с условием, что ноль это «ложь» (False), a не ноль — «истина» (Тruе).
Распространенная ошибка состоит в использовании условного оператора для создания булева значения:
|
Ada |
Result = True;
else
Result = False;
end if;
вместо простого оператора присваивания:
|
Ada |
Запомните, что значения и переменные булева типа являются «полноправными» объектами: в языке С они просто целые, а в Ada они имеют свой тип, но никак не отличаются от любого другого типа перечисления. Тот факт, что булевы типы имеют специальный статус в условных операторах, не накладывает на них никаких ограничений.
Вложенные if-операторы
Альтернативы в if-операторе сами являются операторами; в частности, они могут быть и if-операторами:
if(x1>y1)
if (x2 > у2)
|
C |
else
statement_2;
else
if (хЗ > y3)
statemen_3;
else
statement_4;
Желательно не делать слишком глубоких вложений управляющих структур (особенно if-операторов) — максимум три или четыре уровня. Причина в том, что иначе становится трудно проследить логику различных путей. Кроме того, структурирование исходного текста с помощью отступов — всего лишь ориентир: если вы пропустите else, синтаксически оператор может все еще оставаться правильным, хотя работать он будет неправильно.
Другая возможная проблема — «повисший» else:
if (x1 > у1)
|
C |
statement_1;
else
statement_2;
Как показывают отступы, определение языка связывает else с наиболее глубоко вложенным if-оператором.
