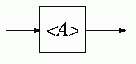
Форма Наура-Бэкуса
При описании синтаксиса конкретных языков программирования приходится вводить большое число нетерминальных символов, и символическая форма записи теряет свою наглядность. В этом случае применяют форму Наура-Бэкуса (ФНБ), которая предполагает использование в качестве нетерминальных символов комбинаций слов естественного языка, заключенных в угловые скобки, а в качестве разделителя - специального знака, состоящего из двух двоеточий и равенства. Например, если правила <L>
® <L> и <L>
® <E> записаны в символической форме, и символ <L> соответствует синтаксическому понятию "список", а символ <E> - "элемент списка", то их можно представить в форме Наура-Бэкуса так: <список>::= <элемент списка><список>,
<список>::= <элемент списка>.
Чтобы сократить описание схемы грамматики, в ФБН разрешается объединять правила c одинаковой левой частью в одно правило, правая часть которого должна включать правые части объединяемых правил, разделенные вертикальной чертой. Используя объединение правил, для рассматриваемого примера получаем: <список>::=<элемент списка><список>|<элемент списка>.
Пред.Страница След.Страница Раздел Содержание
" Формальные языки, грамматики и автоматы"
Основными объектами изучения научного направления "Информатика" являются модели, представимые в памяти компьютера. Методы построения подобных моделей в различных предметных областях основаны на моделях конечных автоматов и формальных грамматик. Широкое использование таких моделей в теоретических исследованиях и разработке систем, используемых на практике, позволяет рассматривать их как одну из основ образования по направлению "Информатика". Главным назначением дисциплины "Формальные языки, грамматики и автоматы" является ознакомление студентов, обучающихся по направлению "Информатика" с основами теории, методами и приемами практического использования аппарата формальных грамматик и конечных автоматов. Изучение дисциплины планируется на 5-ом семестре и включает: курс лекций ( 4 часа в неделю ), лабораторные работы ( 2 часа в неделю ) и курсовую работу.
Лабораторные работы выполняются в компьютерном классе с использованием системы обучения синтаксическому анализу ( ОСА ). Эта система была разработана на кафедре Вычислительной техники в основном силами доц. Разумовского Г.В. и ассистента Кузнецова И.А. Она позволяет автоматизировать некоторые этапы синтеза магазинных автоматов и моделировать их работу.
В курсовой работе студенты реализуют программные модели магазинных преобразователей для некоторых фрагментов языков программирования.
В настоящее время ведется работа по созданию на базе курса лекций, и системы ОСА дистанционной обучающей системы, которая, в отличие от традиционных гипертекстовых представлений материала, должна обеспечивать интерактивное взаимодействие обучающегося с системой, автоматический контроль выполняемых заданий и возможность общения с преподавателем с помощью сетевых средств. Эта работа выполняется без финансовой поддержки в основном силами волонтеров - студентов. Считаю необходимым выразить благодарность моим помощницам Татьяне Карасевой и Светлане Новиковой, выполнившим преобразование текста в формат HTML.
Учитывая существующие трудности, публикацию электронной версии текста пособия предполагается выполнять частями в соответствии с планом пособия по мере их подготовки.
12.05.1998 В.Фомичев

4. Описание перевода и преобразователи.
5. Атрибутные грамматики и преобразователи.
6. Автоматные грамматики и конечные автоматы.
7. Абстрактный синтез автоматов.
8. Переключательные функции и синтез комбинационных схем.
9. Структурный синтез автоматов.
Преобразователи.
4.1. Описание перевода или трансляции .
4.1.1. Синтаксически - управляемые схемы
4.1.2. Перевод, определяемый СУ-схемой.
4.1.3. Простая СУ - схема.
4.1.4. Построение простой СУ - схемы.
4.1.5. Транслирующие грамматики
4.1.6. Входная и выходная грамматики заданной транслирующей грамматики.
4.1.7. Построение транслирующей грамматики по СУ - схеме
4.2. Бесскобочные выражения
4.2.1. Префиксная польская запись.
4.2.2. Вычисление префиксных польских записей.
4.2.3. Постфиксная польская запись.
4.2.4. Вычисление постфиксных польских записей.
4.2.5. Примеры постфиксных польских записей.
4.2.6. Примеры СУ - схем.
4.3. Магазинные Преобразователи.
4.3.1. Определение магазинного преобразователя.
4.3.2. Описание работы магазинного преобразователя.
4.3.3. Перевод определяемый преобразователем.
4.3.4. Построение преобразователя.
4.3.5. Пример построения детерминированного преобразователя.
4.3.6. Порядок построения детерминированного магазинного преобразователя.
4.4. Резюме.
4.5. Упражнения.
4.6. Термины.
Грамматика для описаний
Пусть требуется построить грамматику для описания целых и вещественных переменных. Описание переменных определенного типа должно начинаться указателем типа 'real' или 'int'.
В полном тексте описания описания переменных определенного типа могут повторяться. Например, полное описание может включать три разных описания переменных целого типа. Полное описание должно заканчиваться точкой. В качестве разделителя описаний переменных разных типов примем точку с запятой, а в качестве разделителя переменных одного типа - запятую. Структуру полного описания можно представить в виде двух вложенных списков с разделителями. Внутренний список, рассматриваемый как элемент внешнего списка, представляет собой описание переменных одного типа. Он имеет заголовок в виде указателя типа, за которым следует последовательность идентификаторов, разделенных запятыми. Внешний список использует в качестве разделителя точку с запятой. Схема грамматики рассматриваемого вида может быть записана так:
Г1. 26 : R = { <Z> ® <A2>,
<A2> ®
<B1><C1>,
<C1> ® ;<B1><C1>,
<C1> ® $,
<B1> ® 'real'<L>,
<B1> ® 'int'<L>,
<L> ® <I><K>,
<K> ® ,<I><K>,
<K> ® $ }
Пред.Страница След.Страница Раздел Содержание
Грамматика, задающая последовательность операторов присваивания
Допустим, что в правой части оператора присваивания могут быть использованы только выражения без скобок, описываемые грамматикой Г1. 24. В качестве разделителя операторов в последовательности примем точку с запятой. Учитывая, что последовательность операторов соответствует списку с разделителями в виде точки с запятой, и, используя определенную ранее конструкцию идентификатора, получаем искомую схему грамматики в виде:
Г1. 27 : R = { <U> ® <A3>,
<A3> ® <S><R1>,
<R1> ® ;<S><R1>,
<R1> ® $,
<S> ® <I><B2>,
<B2> ® := <H1>,
<H1> ® <I><R2>,
<R2> ® +<I><R2>,
<R2> ® *<I><R2>,
<R2> ® $}
Пред.Страница След.Страница Раздел Содержание
Грамматики для арифметических выражений
Условимся рассматривать арифметические выражения, использующие только знаки сложения и умножения. Вначале построим грамматику для выражений без скобок. Такие выражения представляют собой цепочки, которые можно рассматривать как списки с разделителями, в которых роль разделителей выполняют знаки операций. В соответствии с этой аналогией получаем схему грамматики, в которой символ <I> обозначает идентификатор, определение которого приведено выше.
Г1. 23 : R = { <H>
® <I><R>,
<R> ® <W><I><R>,
<R> ® $,
<W> ® +,
<W> ® * }.
Чтобы построить грамматику, допускающую использование в арифметических выражениях скобок без вложенности, представим структуру таких выражений в виде списка с разделителями, элементами которого являются выражения без скобок или выражения без скобок, заключенные в скобки. Разделителями этого списка являются знаки операций. Такой структуре соответствует следующая схема грамматики:
Г1. 24 : R = { <G>
® <H><Q>,
<G> ® (<H>)<Q>,
<Q> ® <W><G>,
<Q> ® $ }.
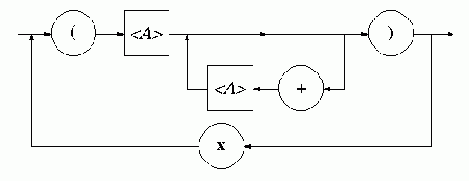
Для построения грамматики арифметических выражений, допускающих применение вложенных скобок, следует предусмотреть возможность использования в качестве элемента списка не только выражения без скобок, но и выражения, в котором могут быть использованы скобки. Схема грамматики, учитывающая эту возможность, может быть записана в виде:
Г1. 25 : R = { <E>
® <G><P>,
<E> ® (<E>)<P>,
<P> ® <W><E>,
<P> ® $ }.
Пред.Страница След.Страница Раздел Содержание
Грамматики, описывающие целые числа без знака и идентификаторы
Целые числа представляют собой последовательность цифр, поэтому их можно рассматривать как списки, элементами которых являются цифры. Используя в качестве аналога грамматику, задающую список без разделителей, получаем схему грамматики для целых чисел в виде:
Г1. 20: <N>
® <D><R>,
<R> ® <D><R>,
<R> ® $,
<D> ® 0 | 1 | ... | 9.
Структуру идентификатора можно представить в виде двух компонентов: начала и основной части. Началом может быть любая из букв, а основная часть представляет собой список без разделителей, элементами которого могут быть либо буквы, либо цифры. Используя выделенные компоненты, получаем схему грамматики вида:
Г1. 21: R ={ <I> ® <C><A>,
<A> ® <C><A>|<D><A>,
<A> ® <C>|<D>,
<A> ® $,
<D> ® 0 | 1 | ... | 9,
<C> ® a | d | c | ... | z }.
Если наложить ограничения на длину идентификатора, например, допустить использование идентификаторов, состоящих только из трех символов, то схема грамматики получается проще.
Г1. 22 : R = { <I> ® <C><A1>,
<A1> ® <C><B>,
<A1> ® <D><B>,
<B> ® <C>,
<B> ® <D>,
<D> ® 0 | 1 | ... | 9,
<C> ® a | d | c | ... | z }.
Пред.Страница След.Страница Раздел Содержание
Грамматики, описывающие условные операторы и операторы цикла
Допустим, что рассматриваются условные операторы, аналогичные используемым в языке Паскаль, с разделителями 'if', 'then', 'else'. В качестве условия в таких операторах разрешается использовать отношения, состоящие из двух идентификаторов, соединенных знаками = и <. Структура такого оператора определяется двумя видами последовательностей фиксированной длины, для описания которых можно воспользоваться простым перечислением компонентов. Первая последовательность определяет полный и сокращенный условные операторы, а вторая - конструкцию "отношение". Схема грамматики, задающая эти последовательности, может быть изображена так:
Г1. 28 : R = { <V>
® .if.<R4><C2>,
<C2> ® .then.<S><C3>,
<C3> ® .else.<S>,
<C3> ® $,
<R4> ® <I><R3>,
<R3> ® < <I>,
<R3> ® = <I>
} .
В этой грамматике <S> определяется схемой грамматики Г1. 27 . Рассмотрим описание операторов цикла, подобных используемым в языке Паскаль, с разделителями 'while', 'do', 'repeat', 'until'. Каждый оператор может быть описан в виде простой последовательности ограниченной длины, в которой используются построенные ранее грамматика Г1. 28 и грамматика Г1. 27 . На практике часто встречаются ситуации, когда удобнее работать с грамматикой, правая часть правил которой начинается терминальным символом. Построение подобных грамматик сводится к тому, что для каждого терминального символа заданной конструкции языка строится отдельное правило. Для рассматриваемых операторов цикла такие схемы грамматик с использованием определенных ранее нетерминальных символов имеют вид:
Г1. 29: R = { <W> ® .while. <R4><C4>,
<C4> ® .do. <S> }
Г1. 30: R = { <W1>
® .repeat.<S><C5>,
<C5> ® .until.<R4>
}.
Пред.Страница След.Страница Раздел Содержание
не имеют никаких ограничений на
Грамматики типа 0, которые называют грамматиками общего вида, не имеют никаких ограничений на правила порождения. Любое правило
r = h ® y
может быть построено с использованием произвольных цепочек
h, y О
(Vт И Va)*. Например,
<T><W> ® <W><T> или x<A>b<C><D> ® x<H><D>.
Пред.Страница След.Страница Раздел Содержание
не допускают использования любых правил.
Грамматики типа 1, которые называют также контекстно-зависимыми грамматиками, не допускают использования любых правил. Правила вывода в таких грамматиках должны иметь вид:
c1<A>c2 ® c1w c2,
где c1,
c2 - цепочки, возможно пустые, из множества
(Vт И Va)*,
символ <А> О Va
и цепочка w О (Vт И
Va)*. Цепочки c1
и c2 остаются неизменными при применении правила, поэтому их называют контекстом (соответственно левым и правым), а грамматику - контекстно зависимой.
Грамматики типа 1 значительно удобнее на практике, чем грамматики типа 0, поскольку в левой части правила заменяется всегда один нетерминальный символ, который можно связать с некоторым синтаксическим понятием, в то время как в грамматике типа 0 можно заменять сразу несколько символов, в том числе и терминальных.
Например, грамматика:
Г1. 4:
Vт = {a, b, c, d}, Va = {<I>, <A>, <B>}
R = { <I> ® aA<I>,
A<I> ® AA<I>,
AAA ® A<B>A,
A ® b,
b<B>A ® bcdA,
b<I> ® ba }
является контекстно-зависимой, поскольку второе и шестое правила имеют непустой левый контекст, а третье и пятое правила содержат оба контекста. Вывод в такой грамматике может иметь вид:
<I> Ю a<A><I>
Ю a<A><A><I> Ю ab<A><I> Ю abb<I> Ю abba.
Пред.Страница След.Страница Раздел Содержание
Правила вывода таких грамматик имеют
Грамматики типа 2
называют контектно-свободными и бесконтекстными грамматиками ( КС-грамматики или Б-грамматики).
Правила вывода таких грамматик имеют вид:
<A> ® a,
где <A> О
Va и a О (Vт И Va)*.
Очевидно, что эти правила получаются из правил грамматики типа 1 при условии c1
= c2 = $. Поскольку контекстные условия отсутствуют, то правила КС-грамматик получаются проще, чем правила грамматик типа 1. Именно такие грамматики используются для описания языков программирования. Примером КС-грамматики может служить следующая:
Г1. 5:
Vт = {a, b}, Va = {<I>},
R = { <I> ®
a<I>a,
<I> ® b<I>b,
<I> ® aa,
<I> ® bb}.
Эта грамматика порождает язык, который состоит из цепочек, каждая из которых в свою очередь состоит из двух частей, цепочки
b О Vт* и зеркального отображения этой цепочки b'.
L( Г5 ) = { bb' | b ОVт+},
где Vт+ - это множество Vт*
без пустой цепочки. С помощью правил этой грамматики может быть построена, например, следующая цепочка:
<I> Ю a<I>a
Ю ab<I>ba Ю aba<I>aba
Ю ababbaba.
Пред.Страница След.Страница Раздел Содержание
в таких грамматиках имеют вид:
Грамматики типа 3
называют автоматными грамматиками (А - грамматиками). Правила вывода в таких грамматиках имеют вид:
<A> ® a
или <A> ® a<B>
или <A> ® <B>
a,
где a О Vт, <A>, <B> О Va, причем грамматика может иметь только правила вида <A>
® a<B> - правосторонние правила, либо только вида <A> ® <B>a
- левосторонние правила. Примерами автоматных грамматик могут служить правосторонняя грамматика Г1. 6
и левосторонняя грамматика Г1. 7.
Г1. 6:
Vт = {a, b}, Va = {<I>, <A>},
R = { <I> ® a<I>,
<I> ® a<A>,
<A> ® b<A>,
<A> ® b<Z>,
<Z> ® $ }.
Г1. 7:
Vт = {a, b}, Va = {<I>, <A>},
R = { <I> ® <A>b,
<A> ® <A>b,
<A> ® <Z>a,
<Z> ® <Z>a,
<Z> ® $ }.
Эти грамматики являются эквивалентными и порождают язык
L(Г7) = {a...ab...b | n,m > 0}.
Между множествами языков различных типов существует отношение включения:
{ L типа 3 } М
{ L типа 2 }
М{ L типа 1 } М{ L типа 0}.
Доказано, что существуют языки типа 0, не являющиеся языками типа 1, языки типа 2, не являющиеся языками типа 1, и языки типа 3, не являющиея языками типа 2.
Учитывая, что наибольшее практическое применение находят грамматики типа 2 и типа 3, дальнейшее изложение посвящается рассмотрению именно этих типов грамматик.
Пред.Страница След.Страница Раздел Содержание
Итерационная форма
Для получения более компактных описаний синтаксиса применяют итерационную форму описания. Такая форма предполагает введение специальной операции, которая называется итерацией и обозначается парой фигурных скобок со звездочкой. Итерация вида {a}* определяется как множество, включающее цепочки всевозможной длины, построенные с использованием символа a, и пустую цепочку.
{a}* = {$, a, aa, aaa, aaaa,...}.
Иcпользуя итерацию для описания множества цепочек, задаваемых символическими правилами, для списка получаем:
<L> ® <E> {<E>}*.
Например, описание множества цепочек, каждая из которых должна начинаться знаком # и может состоять из произвольного числа букв x и y, может быть представлено в итерационной форме так:
<I> ® #{x | y}*
.
В итерационных формах описания наряду с итерационными cкобками часто применяют квадратные скобки для указания того, что цепочка , заключенная в них, может быть опущена. С помощью таких скобок правила:
<A> ® x<A>y<B>z и <A>
® x<B>z
могут быть записаны так:
<A> ® x[<A>y]<B>z.
Пред.Страница След.Страница Раздел Содержание
<L>
, то получим правила грамматики в виде: Г1. 15: <L>
® a<R>,
<R> ® a<R>,
<R> ® $.
2) В предыдущей задаче предполагалось, что список <L>
должен содержать хотя бы один элемент. Если же допустить, что множество цепочек, порожденных правилами грамматики, может включать пустой символ, то к построенным правилам нужно добавить еще одно правило <L>
® $ . В этом случае набор правил имеет вид :
Г1. 16: <L> ® a<R>,
<R> ® a<R>,
<R> ® $,
<L> ® $.
3) Рассмотрим построение списка, между элементами которого должны стоять разделители. Выберем в качестве разделителя запятую. Простейший список, как и в предыдущем случае, состоит из одного элемента, а построение списка из нескольких элементов может быть выполнено приписыванием к уже построенной части списка разделителя с элементом списка. Правила, соответствующие этому построению, имеют вид:
Г1. 17: <L> ® a<R>,
<R> ® ,a<R>,
<R> ® $.
4) Если список с разделителями может быть пустым, то приведенный выше набор правил нужно дополнить еще одним правилом с пустой правой частью. В результате получим: Г1. 18: <L> ® a<R>,
<R> ® ,a<R>,
<R> ® $,
<L> ® $.
В общем случае, если описано множество цепочек, представляющих собой некоторый язык, и требуется построить грамматику, порождающую это множество цепочек, то следует поступать так:
1) Выписать несколько примеров из заданного множества цепочек.
2) Проанализировать структуру цепочек, выделяя начало, конец, повторяющиеся символы или группы символов.
3) Ввести обозначения для сложных структур, состоящих из групп символов. Такие обозначения являются нетерминальными символами искомой грамматики.
4) Построить правила для каждой из выделенных структур, используя для задания повторяющихся структур рекурсивные правила.
5) Объединить все правила.
6) Проверить с помощью выводов возможность получения цепочек с разной структурой.
Пред.Страница След.Страница Раздел Содержание
Левый и правый выводы
Среди всевозможных выводов наибольший интерес представляют следующие два типа выводов.
| Определение. Если при построении вывода цепочки a
при каждом применении правила заменяется самый левый нетерминальный символ, то такой вывод называется левым или левосторонним выводом a. Если при построении вывода a, всегда заменяется самый правый нетерминальный символ промежуточной цепочки, то вывод называется правым или правосторонним выводом a. |
Например, приведенный выше вывод цепочки i * i + i в грамматике Г1. 9 является левосторонним выводом. Следует отметить, что различным выводам цепочки i+i в грамматике
Г1. 9 соответствует одно и то же синтаксическое дерево. Аналогичная ситуация имеет место и при выводе цепочки
i * i + i.
Пред.Страница След.Страница Раздел Содержание
Неоднозначные и эквивалентные грамматики
Существуют грамматики, в которых одна и та же цепочка может быть получена с помощью различных выводов. Например, в грамматике Г1. 10 цепочка abc
может быть получена с помощью двух различных выводов, и ей соответствуют два различных синтаксических дерева.
Г1. 10:
Vт = {a, b, c, d}, Va = {<I>, <A>, <B>},
R = { <I> ® <A><B>,
<A> ® a,
<A> ® ac,
<B> ® b,
<B> ® cb}.
Первый вывод этой цепочки имеет вид :
1) <I> Ю <A><B>
Ю <A>b Ю acb,
а второй можно получить так :
2) <I> Ю <A><B>
Ю <A>cb Ю acb.
Этим выводам соответствуют разные синтаксические деревья и разборы :

Следующая грамматика также допускает построение одной и той же цепочки с помощью двух выводов, имеющих разные синтаксические деревья.
Г1. 11:
Vт = {0, +}, Va = {<I>},
R = { <I> ® 0,
<I> ® <I>
+ 0,
<I> ® 0 +<I>
}.
Два вывода этой грамматики, порождающие одинаковые цепочки, имеют вид:
1) <I> Ю <I>
+ 0 Ю <I> + 0 + 0 Ю 0 + 0 + 0,
2) <I> Ю 0 + <I> Ю 0 + 0 +<I> Ю 0 + 0 + 0,
а синтаксические деревья, соответствующие этим выводам, можно изобразить так:

Рассмотренное свойство грамматик называется неоднозначностью. Оно может быть определено следующим образом.
| Определение. Цепочка языка L(Г) называется неоднозначной, если для её вывода существует более чем одно синтаксическое дерево. Если грамматика Г порождает неоднозначную цепочку, то она называется неоднозначной. |
Неоднозначность может существовать не только в искусственных языках. Хорошо известно, что в естественных языках могут быть предложения, допускающие неоднозначное написание. Например, "Пальто испачкало окно". В этой фразе не ясно, что является подлежащим, а что дополнением. Другим примером служит английская фраза: "They are flying planes", которая может быть понята двояко: "Они пилотируют самолет" или : Это летящие самолеты".
Свойство неоднозначности является крайне нежелательным для искусственных языков, поскольку оно не позволяет однозначным образом восстановить дерево вывода по заданной цепочке языка.
В общем случае можно сделать следующий вывод:
1) каждой цепочке, выводимой в грамматике, может соответствовать одно или несколько синтаксических деревьев,
2) каждому синтаксическому дереву могут соответствовать несколько выводов,
3) каждому синтаксическому дереву соответствует единственный правый и единственный левый выводы.
Кроме того, следует подчеркнуть, что один и тот же язык может быть получен с помощью различных грамматик.
| Определение. Две грамматики Г1 и Г2 называются эквивалентными, ecли они порождают один и тот же язык, т.е. L(Г1) = L(Г2). |
Описание списков
В качестве первых примеров рассмотрим построение грамматик для последовательностей символов и последовательностей символов с разделителями. Такие последовательности часто называют списками.
1) Обозначим элемент последовательности a. Простейшая последовательность может состоять из одного элемента a. Все другие последовательности могут быть получены путем приписывания к уже построенной последовательности еще одного элемента. Если обозначить построенную часть последовательности нетерминальным символом <R>, а последовательность символом
Определение формальной грамматики и языка
Изучение предмета начнем с определения первичных понятий.
Первичные понятия
| Определение. Конечное множество символов, неделимых в данном рассмотрении, называется словарем
или алфавитом, а символы, входящие в множество, - буквами алфавита. |
Например, алфавит A = {a, b, c, +, !}
содержит 5 букв, а алфавит B = {00, 01, 10, 11}
содержит 4 буквы, каждая из которых состоит из двух символов.
| Определение. Последовательность букв алфавита называется словом или цепочкой
в этом алфавите. Число букв, входящих в слово, называется его длиной. |
Например, слово в алфавите A a=ab++c
имеет длину l(a) = 5, а слово в алфавите B b=00110010 имеет длину l (b) = 4.
Если задан алфавит A, то обозначим
A* множество всевозможных цепочек, которые могут быть построены из букв алфавита A. При этом предполагается, что пустая цепочка, которую обозначим знаком $, также входит в множество A*.